Research Data Management and Publishing
Open Research Data
The word ’data’ (singular ’datum’) originates from Latin, literally: (things) given, from dare to give. (Collins English Dictionary).
Essentially, data is something that describe the objectively existing matters.
Data is raw material, which enable the structuring, categorising and measuring of the world. Data become valuable when people use it.
Shortly Reserach Data is any information collected and processed to produce original research results.
In Concordat on Open Research Data, developed in UK, the following definition of research data has been adopted:
Research data are the evidence that underpins the answer to the research question, and can be used to validate findings regardless of its form (e.g. print, digital, or physical). These might be quantitative information or qualitative statements collected by researchers in the course of their work by experimentation, observation, modelling, interview or other methods, or information derived from existing evidence. Data may be raw or primary (e.g. direct from measurement or collection) or derived from primary data for subsequent analysis or interpretation (e.g. cleaned up or as an extract from a larger data set), or derived from existing sources where the rights may be held by others. Data may be defined as ‘relational’ or ‘functional’ components of research, thus signalling that their identification and value lies in whether and how researchers use them as evidence for claims. They may include, for example, statistics, collections of digital images, sound recordings, transcripts of interviews, survey data and fieldwork observations with appropriate annotations, an interpretation, an artwork, archives, found objects, published texts or a manuscript.
Open research data is the research data made accessible to others via Open Access, for sharing and re-using, provided that re-users would cite the original data. We can say that the main characteristic by which we can define open research data is its accessibility.
Open data of the public sector (public data, government data) are the data created by the public sector and held in data sets without any limits to their accessibility. They form the basis for public services and decisions. When public data are used in research, they also become part of research data. The publc data can be found in Estonian Open Government Data Portal.
Data can be classified based on different characteristics:
-
Quantitative and qualitative data
Quantitative data can be expressed in numbers – measures or weights, ratio scale (1-100), yes/no decisions, etc.
Qualitative data cannot immediately be expressed in numbers, such as text, image, video, etc. Qualitative data can be analysed and converted into numerical data.
-
Structured and unstructured data
Structured data is the data organised in a way where each variable has a corresponding value and these variable-value pairs form a database. Such data can be computer-processed and searched by using algorithms and query languages. The result of data processing can be visualised and used for creating models and simulations.
Structured data are related to the term ‘linked data’. Data are structured in a way which allows to link them according to a standard; together they form the semantic web. DBPedia is an example of open linked data.
Unstructured data have no fixed model or structure, it is difficult to process it with computers.
-
Primary and secondary data
Primary data are the data collected by the researchers themselves. Data which have not yet been processed or analysed are called raw data.
Secondary data is data previously collected by the researcher himself or by someone else. It is a reuse of data.
-
Metadata
Metadata are the data about data, which should be openly accessible to all even if the original data are not accessible.
-
Big data and “long tail” data
Big data are characterised by a large volume of data, continuous and high speed of data processing, and extremely various types of data (3V: Volume, Velocity, Variety). Big data are the structured data which can be automatically processed.
For example, data from the Internet of Things (IoT), meaning the data from devices that are constantly saving and sharing data, can be called big data.
Big data can also be open data, but its main characteristic is its large volume.
However, most of the present-day research is dealing with data of smaller volume, which is called “long tail data”, because when visualised on a graph, where one axis is the volume of data and the other axis is the number of relevant data sets, the customary research forms this long and thin tail on the number axis. The volume of the data is small, only certain types of data are collected and processed at the same time, the data collecting and processing methods are traditional and they may be tailored for studying some certain problem.
Culina, A., M. Baglioni, T.W. Crowther, M.E. Visser, S. Woutersen-Windhouwer, and P. Manghi. 2018. Navigating the unfolding open data landscape in ecology and evolution. Nature Ecology & Evolution 2: 420-426
Long tail of science. Dispersed scientific research that is conducted by many individual researchers/teams, and is often of a limited spatial and temporal scale. Data produced in the long tail tend to be small in volume, and less standardized within the same field of study. The majority of scientific funding is spent on this type of research.
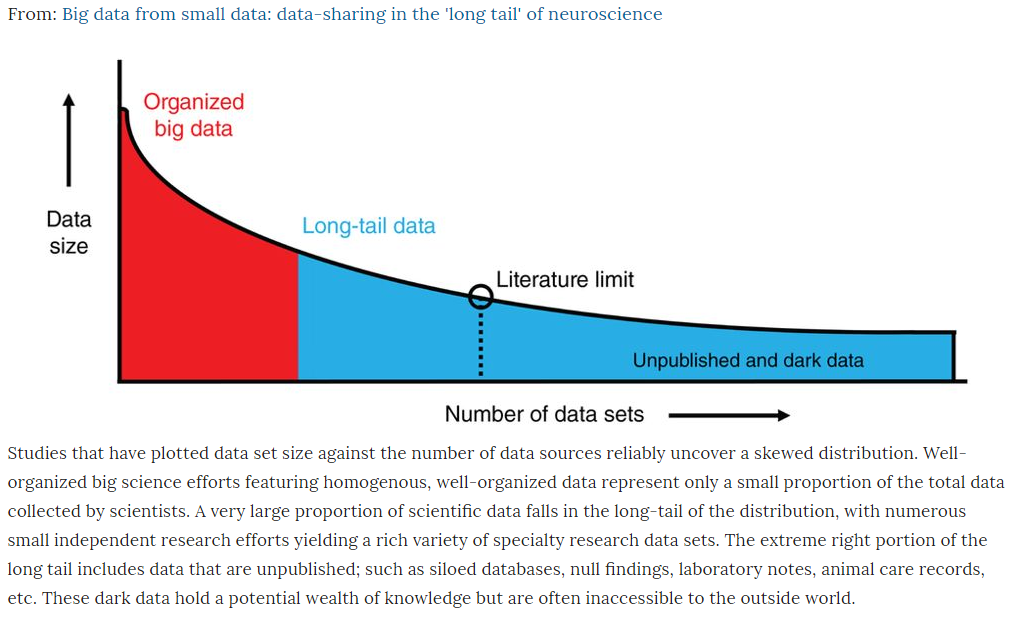
Ferguson, A. R., Nielson, J. L., Cragin, M. H., Bandrowski, A. E. & Martone, M. E. Big data from small data: data-sharing in the ‘long tail’ of neuroscience. Nat. Neurosci. 17, 1442–1447 (2014)