Research Data Management and Publishing
FAIR Data
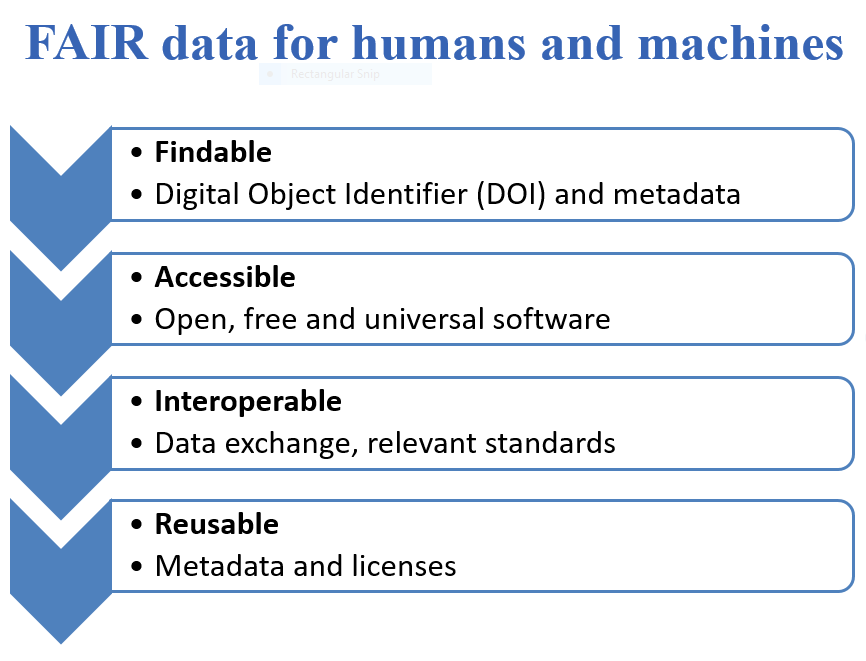
By FAIR principle data should be findable and accessible on the Internet, interoperable with other computer systems and reusable both for people and computers.
The acronym FAIR is derived from the words Findable, Accessible, Interoperable and Reusable.
Regarding the volume of data which is handled today, it is unthinkable that the researcher should solely manually process the data.
The FAIR principles are a direct result of the need for an infrastructure, which could support the machine readability of data to facilitate the finding, understanding and sharing of it and, due to this, to increase the transparency and reproducibility of research.
Sharing open research data had been topical already for several years, up to the moment, when it was realised that the effort of researchers and proper data management are still not sufficient for making data reusable for other researchers.
In 2014, a group of representatives of different stakeholders started to develop the principles which would ensure the machine readability of data. In 2016, the results of this effort were published as the FAIR principles.
The FAIR data principles source article:
Wilkinson, M.D. et al.,. (2016). The FAIR Guiding Principles for scientific data management and stewardship, Scientific Data 3, https://doi.org/10.1038/sdata.2016.18
These 15 principles point to the roles of researchers and the supporting infrastructure.
Below, you can find a short explanation at each group of principles; a longer discussion will follow later.
The FAIR Guiding Principles
To be Findable:
F1. (meta)data are assigned a globally unique and persistent identifier
F2. data are described with rich metadata (defined by R1 below)
F3. metadata clearly and explicitly include the identifier of the data it describes
F4. (meta)data are registered or indexed in a searchable resource
F1. (meta)data are assigned a globally unique and persistent identifier
Fulfilment of the conditions F1-F4 should mostly be ensured by the creators of the data, who have to describe their data by adding as complete set of metadata as possible and getting a DOI for their data set.
To learn how to do it, read the chapters Metadata, Repositories and DOI in your learning materials.
To be Accessible:
A1. (meta)data are retrievable by their identifier using a standardized communications protocol
A1.1 the protocol is open, free, and universally implementable
A1.2 the protocol allows for an authentication and authorization procedure, where necessary
A2. metadata are accessible, even when the data are no longer available
While the existence of metadata and DOI are the prerequisites for finding the data, the conditions A1-A2 emphasise that metadata should be standardised. Metadata standards include more general and better known standards, as well as those which are narrowly specific to certain fields. The task of a researcher is to select the most suitable standard for describing their data.
Data processing always uses some kind of software. Data are well accessible if the software used is as universal as possible and free of charge. However, sometimes it is necessary to develop one’s own software for some specific purpose. In this case, software is subject to all the same requirements as data.
Read the chapter Metadata in learning materials.
To be Interoperable:
I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
I2. (meta)data use vocabularies that follow FAIR principles
I3. (meta)data include qualified references to other (meta)data
The machine readability and interoperability of data should be ensured by information systems. It depends on the structure of the database and on which dictionaries, ontologies and taxonomies are used.
Much of technical metadata are created automatically by information systems.
More about this subject can be found in the chapter Repositories.
To be Reusable:
R1. meta(data) are richly described with a plurality of accurate and relevant attributes
R1.1. (meta)data are released with a clear and accessible data usage license
R1.2. (meta)data are associated with detailed provenance
R1.3. (meta)data meet domain-relevant community standards
Having found the data suitable for reusing in repositories, it is necessary to understand the data and place it into a context in order to evaluate whether it can be used in your own work. Standard metadata and the accompanying documentation can help you in evaluating the origin and completeness of the data.
In reusing data, it is important to understand how licences permit the usage of data, and how to cite data in a correct way.
Read the chapters on documenting, metadata and licences.
It is necessary to point out that FAIR data and open data are not synonymous. FAIR data are created in the cooperation of a researcher and e-infrastructure, but only the researcher can decide, based on the content of the data, whether it is open data.
The FAIR principles were officially recognised at the summit of the G20 countries in Hangzhou, China on 5th of September 2016. Long-term studies on the state of the art and FAIR data have been conducted since then, with the latest report published for 2018-2020. This shows that awareness of FAIR principles has increased, but is still too low.

Science, Digital; Hahnel, Mark; McIntosh Borrelli, Leslie; Hyndman, Alan; Baynes, Grace; Crosas, Merce; et al. (2020): The State of Open Data 2020. Digital Science. Report. https://doi.org/10.6084/m9.figshare.13227875.v2
It is probably easier to understand the role and benefits of FAIR data when data collection is expencive or you have a single chance to collect the data or carry out observations.
In Australia a FAIR data self assessment tool has been developed by the ARDC. It is provided purely for educational and informational purposes: FAIR self assessment tool.
Making data FAIR needs considerable time, knowledge, skills and motivation.
The FAIR data ecosystem embodies data, components of the information system and their interaction, and a common network.The ecosystem consists of data policies, data management plans, standards, permanent identifiers, repositories and automated workflows among them, which all together comprise a network. For the sustainable operation of this ecosystem, it is necessary to develop services, tools and e-infrastructure and to ensure sufficient funding.
Recently a project was carried out in Nordic and Baltic region. The project deliverable describes ways of developing a FAIR research culture based on incentives. It explores the existing incentive structures in place for FAIR research practices in the Nordics and Baltics and promotes additional efficient incentives based on findings from a qualitative study using a multi-stakeholder approach. It also reflects on the expected impacts an increased level of FAIRness may have on the Nordic and Baltic research communities.
Nordling, Josefine, Assinen, Pauli, Fuchs, Siiri, Kuusniemi, Mari Elisa, Lembinen, Liisi, Mihai, Hannah, Alaterä, Tuomas, Meerman, Bert, Vecpuise, Elza, & Ivarsson, Lars-Owe. (2022). D4.4 Report and recommendations on FAIR incentives and expected impacts in the Nordics, Baltics and EOSC. Zenodo. https://doi.org/10.5281/zenodo.6881009
Two archetypes were created: The archetypes are not real persons, representing extremes in the attitudes towards and awareness of the FAIR principles. Master answers to quotes like: “Highlighting success stories and benefits is an important factor here” and “champions should be highlighted as role models, individual researchers, research groups, but also research areas” (figure 5). We use them to explore: – What can we learn from the Masters? – How can we motivate Newbies to become Masters?

There is a FAIR Cookbook guiding you through the key steps of a FAIRification journey based on examples.
Additional reading about FAIR data and some useful resources were published in Nature Index database (11.02.2019):
“A love letter to your future self”: What scientists need to know about FAIR data
Prof. Susanna-Assunta Sansone, Associate Director of Oxford eResearch Centre and Associate Professor (FAIR Data Science) at the University of Oxford, discusses her journey and work with and for a variety of communities to implement an ecosystem of resources to enable and support data: