Research Data Management and Publishing
Collection and Organisation of Data
Collection and organisation of data form the basis for successful and effective research. Decisions made at this phase of research are very difficult, if not impossible, to reconsider and change later, since they involve people, their tasks and training. Data collection requires suitable hardware and software.
When collecting data, it is necessary to explain:
- why the data will be collected
- how the data will be obtained
- which types of data and formats will be used
- how large will be the expected volume of the data
Having decided upon these matters, the next step is to establish the ways for organising the data and files.
How will the data be obtained?
Data can be collected by the researchers themselves; it is also possible to (re)use the data collected earlier by the researchers themselves, to use open public data, to reuse the data collected by others, or to buy the data.
Using of one’s own earlier data requires that the data are correctly managed, and their content can be understood and technically processed with modern IT tools.
The data collected by others can be found in open data repositories (see repositories); open public data can be found in national registries.
The data collected by commercial enterprises form the basis for data economy and should, as a rule, be bought from its owner.
When using the data collected by others, it is necessary to find out its proper ownership and under which conditions such data can be used.
Data volume
A large volume of data may cause large expenditure in data exchange and long-term storing of data. Many repositories have limited the volume of data and additional fee has to be paid when exceeding this limit. The limit may differ greatly, extending from 2GB to 10 GB.
The volume of data sets requirements to the hard- and software, e.g., geospatial data cannot be stored in the format of traditional spreadsheets.
Volume of the data should be considered when thinking about storing, making backups and providing access to your data. Evaluate the possible volume of the data at the end of the project (MB, GB, TB) and decide, whether you will have enough space for saving and sufficient technical support for handling your data.
Data formats
Identify your data formats and give the reasons why they were chosen. If possible, use open formats (e.g., TXT, RTF, HTML, XHTML, PDF, JPEG, PNG, SVG) and open standards. If you use commercial software, you may face a risk that it will not be supported, or its price will not be affordable any more. Using of standardised formats, which allow data exchange, will ensure the long-time re-using of the data.
Some useful suggestions:
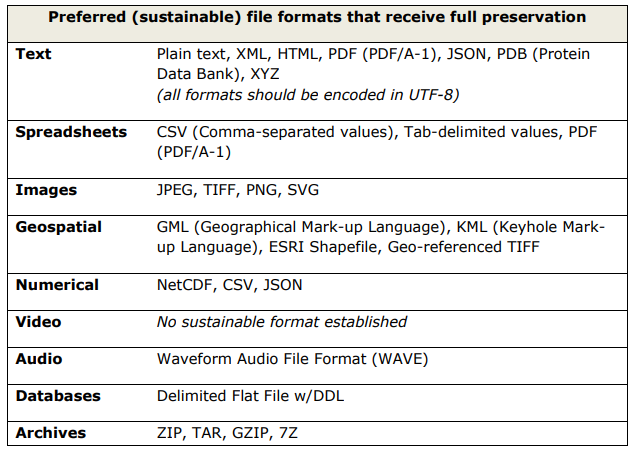
For long-term storage, data are deposited in data repositories. It can happen that a repository does not offer all services (visualisation, bibliometrics, altmetrics, statistics) for all existing formats. This must be mentioned in the terms and conditions of use of the repository, so that the researchers can opt for some other format or another repository.
Data description and data types
Describe the data that will be created in the course of your work. Describe the content and scope of your data, indicating, e.g., instrumental data, measurement data, monitoring data, survey data, observational data, physical objects, audio and video recordings, texts, etc.
Data can also be classified on other grounds, such as the historical, public, reusable, dynamic, etc., data.
You also need to decide which data will be worth long-time storing. Storing data in a repository is costly for the operator of the repository, and not all data need to be stored or made open. This aspect has to be evaluated with respect to the transparency and reproducibility of the results.
Organisation of data
Organisation of files before the collection of data is a complicated task:
- You need to think ahead for a number of years about how the data may change
- How new data and new formats will be added?
- How backups will be made? How are the files related with each other?
- How will these relations be reflected?
- How will the existing data be supplied with metadata?
According to The State of Open Data Report 2018, in 46% of the cases, the reason for not sharing the data was the fact that the data was not organized in a presentable format.
The reasonable organization of files is based on simple and logical naming of files.
However, as submission of data with a research paper is a common practice only in recent years, it may be necessary to rename previously collected data files or reused data files.
File naming
The structure of logically named files and well-organised folders facilitates the finding of data and tracking of changes. It is useful to add the following elements to a file name:
- ID of the project or a short and meaningful name (mnemonics!)
- file type (for example document file, database file, presentation file, graphic file etc)
- date
- name of the creator of the file (initials, pseudonym)
- number of the version
- status
Use everything which has already been standardised (e.g., ISO 8601 Date and Time Formats), or commonly recognised abbreviations (identifiers of the country and monetary units, gender identifiers).
Copying files to multiple locations is not a good practice. If for some reason the same file should be in multiple locations, a shortcut should be created.
File renaming
If there is already a larger amount of data collected for the project and you need to rename all the files at the same time, then doing it manually can be rather inconvenient.
To make file renaming simpler you can choose from the tools named below. These tools allow to rename multiple files at the same time, make replacements, reorganise, delete, add numeration, add prefixes and suffixes, change upper- and lowercase, manipulate with time formats. You can also rename image and audio files and file extensions. Before saving it is possible to see the preview and restore original filenames. Also, regular expressions are supported which allow to use more complex text manipulations.
-
Bulk Rename Utility
- For Windows operating system (adapts all versions)
- Free for regular users, licence is needed for organisations and commercial use
- Supports ID3 and EXIF meta tags
- Can be used with Windows File Properties application
-
ReNamer
- For Windows operating system
- Available in different languages
- Supports ID3v1, ID3v2, EXIF, OLE, AVI, MD5, CRC32, SHA1 tags
-
Transnomino
- For Mac OS operating system
- Supports ID3 and EXIF tags
-
Inviska
- For Linux (Windows and Mac OS also) operating system
- Supports ID3v2 and FLAC tags
-
Metamorphose
- For Linux (Windows and Mac OS also) operating system
- Supports Exif and ID3 tags
You can read more detailed information about the functions of these tools from their homepages, documentation or under FAQ.
Windows, Mac OS and Linux operating systems themselves enable simple multiple file renaming too but with vastly less functionality.
Organisation of files
The structure and hierarchy of files heavily depends on the nature of the project. The continuity all through the project is ensured only when one and the same system is applied all through the project by all the participants. The structure may also be determined by the tools used. Possible versions can be:
- Files are sorted by years or
- sorted by the types of data (text, spreadsheets, images, database) or
- sorted by the type and nature of data (survey data, target groups, monitoring data)
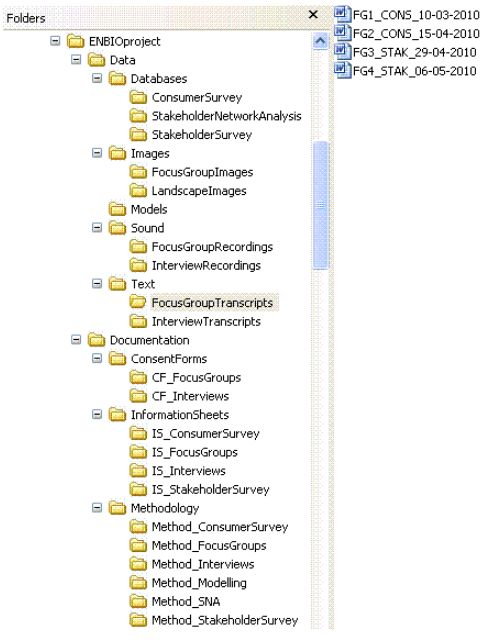
It seems reasonable to present the above-mentioned information in a table, if the data types allow it. More columns with important information can also be added to the sample table provided, such as who is responsible for collecting the data, what metadata will be added to the files, whether the data will be opened or closed, and so on.
|
Technique of collecting data |
Type of data |
Format |
Volume |
File identity |
Note |
|
Interview |
Audio recording |
WAVE, WMA or MP3 |
|
Int.rec. |
Semi-structured interviews in Estonian |
|
|
Transcript and summary |
RTF & PDF |
|
Int.trans. |
Transcript in Estonian, summary in English |
|
Observation |
Observation note |
RTF & PDF |
|
Obs.note. |
Participant observation by researcher |
|
|
Photo documentation |
JPEG |
|
Obs.photo. |
Taken by researcher |
|
Focus Group Discussion |
Audio recording |
WAVE, WMA or MP3 |
|
FGD.rec. |
Focus group on…. |
|
|
Transcript and summary |
RTF & PDF |
|
FGD.trans. |
Transcript in Estonian, summary in English |
|
|
Photo documentation |
JPEG |
|
FGD.photo. |
|
|
Workshop |
Audio recording |
WAVE, WMA or MP3 |
|
Work.rec. |
Workshop on … |
|
|
Transcript and summary |
RTF & PDF |
|
Work.trans. |
Transcript in Estonian, summary in English |
|
|
Photo documentation |
JPEG |
|
Work.photo. |
Taken by the researcher |
|
|
Video documentation |
MP4 |
|
Work.vid. |
Produced by the participants |
|
Survey – questionnaire |
Survey data |
MS Excel & PDF |
|
Surv. |
Open questionnaire model, link |
|
Document study |
Archive |
PDF, ZIP, or JPEG |
|
Arch. |
Archives gathered from relevant sources, |
|
Scoping survey
|
Articles, text |
|
|
Scop.surv |
List of selected articles |
|
Fieldwork
|
Notes, memos |
doc |
|
Notes |
Linked to relevant type |
It is very important to describe file naming and organising in README file. This is a text file that gives information about other files and assures that all users understand data the same way. It is beneficial to the researcher who may want to reuse his/her data after some time has passed and also to other people who want to use this data.
README file is saved in .txt or .md format and is uploaded together with the dataset.
README file should be always named README (not readme, read_me, about etc)!
README file should consist of following content:
-
Introductory information
- Title of the dataset
- Short descriptions about the content of data files
- Who are the users of this dataset and to whom this can be useful
-
Methodological information
- Method description for collecting or generating the data, as well as the methods for processing data, if data other than raw data are being contributed
-
Data specific information
- Full names and definitions (spell out abbreviated words) of column headings for tabular data
- Units of measurement
- Definitions for codes or symbols used to record missing data
- Specialized formats or abbreviations used
-
Sharing and access information
- Licences and restrictions placed on the dataset
An example what else README file should contain: