
The 5th International Symposium on Applied Phonetics
Invited speakers
Plenary talks
Ocke-Schwen Bohn (Aarhus University)
30 September 2024, 10:00, University of Tartu Main Building, Ülikooli 18. Recording of the presentation is available online
At first sight, it may appear as if the ability to produce and perceive the sounds of a nonnative language inevitably declines with age. This superficial impression has often been interpreted as providing support for the Critical Period Hypothesis (CPH), which claims that language learning ability is severely compromised after puberty because “the brain behaves as if it has become set in its ways” [1].
This presentation addresses three problems which any maturational account of assumed age difference in language learning (like the CPH) encounters: First, that “age” is a variable that may (or may not) be associated with biological and psycholinguistically relevant maturation or, more plausibly, with differences in the quality and quantity of linguistic input across the life span. Secondly, the presentation will review empirical findings which address the question of whether successful speech learning is restricted to a prepubescent window of opportunity. The conclusion from this review is that studies which seem to provide support for the CPH are often flawed either because of confounding variables (e.g., differences in language experience between young and older learners) or because of misleading data analyses and presentations. Third, this presentation will present recent evidence from our lab on the ability of seniors (60-78 years old) to restructure their sound systems in a perceptual training regime. Comparisons with younger trainees revealed no age differences in the efficacy of training (i.e., increase in perceptual accuracy) and no age differences in the training trajectory over 10 training sessions.
The presentation concludes that the existing evidence strongly supports one of the main tenets of current models of nonnative speech learning, the PAM-L2 [2] and the SLM-r [3], which claim that speech learning ability remains intact across the life span. As far as speech learning ability is concerned, time is ripe to recognize Critical Period Hypothesis for what it is: a neuromyth [4].
[1] E. H. Lenneberg, Biological foundations of language. New York: Wiley 1967.
[2] C. T. Best and M. Tyler. “Nonnative and second-language speech perception,” in Language experience in second language speech learning, O.-S. Bohn and M. J. Munro, Eds. Amsterdam: J. Benjamins, 2007, pp. 13-34.
[3] J. E. Flege and O.-S. Bohn. “The revised speech learning model (SLM-r),” in Second language speech learning: Theoretical and empirical progress, R. Wayland, Ed. Cambridge: Cambridge Universitry Press, K Macdonald et al. 2021, pp. 3-83.
[4] K. Macdonald et al. “Dispelling the myth: Training in education or neuroscience decreases but does not eliminate beliefs in neuromyths,” Frontiers in Psychology 8, pp. 1314, 2017.
Sofia Strömbergsson (Karolinska Institutet)
30 September 2024, 17:00, University of Tartu Main Building, Ülikooli 18. Recording of the presentation is available online
The number of correct consonants, or the number of correct grammatical inflections in children’s utterances, are examples of measures of speech and language competence in children. In speech-language pathology research, measures like these are central in quantifying speech and language difficulties, and in separating groups of children who have a speech/language disorder from those who follow a typical trajectory. And in clinical practice, measures like these form the basis of developmental milestones, to which the observed speech and language in a specific child are compared. Producing canonical babbling by 10 months [1], combining words by 24 months [2], and having acquired the majority of Swedish consonants by the age of 5 [3], are all examples of such milestones. In clinical practice, the comparison to norms is important when identifying risk for later difficulties, and deciding whether intervention is needed. In this talk, I will examine the potential conflict between measures used when identifying disorders, and what aspects of speech, language and communication actually matter in daily life for children with speech/language disorders.
At a closer look, the boundary between ‘correct’ and ‘incorrect’ is rarely clear-cut. The assessment of whether a consonant is produced ‘correctly’ or not involves a reduction of phonetic detail that may convey different degrees of ‘correctness’ [4]. This reduction of detail may obscure important insights into a child’s phonological competence, as evidenced in observations of covert contrast [4], [5]. ‘Covert contrast’ refers to when a child expresses a measurable phonetic distinction between speech sounds, which goes unnoticed to the assessor – or which, at least, is not documented in transcription. In other words, the way we document articulation will affect how we characterize children’s speech.
Information concerning communication in daily life is an integral part of clinical assessment. For children with speech difficulties, clinicians routinely collect information from caregivers concerning how children make themselves understood in everyday contexts. A well-established instrument for such assessment is the Intelligibility in Context Scale (ICS) [6], which can be used to identify departures from expected development. However, closer inspection is needed for understanding when and why intelligibility is disrupted [7]. Assessments of intelligibility rely not only on information in the speech signal, but also on the assessor and their degree of training [8], their experience with the target language [9], and their familiarity with the speech material [10]. One may question, therefore, whether speech-language pathologists (SLPs) are indeed representative assessors of speech intelligibility. At least, one might acknowledge a need to calibrate SLP assessments against other listeners’ assessments.
When used as a descriptor of speech, ‘intelligibility’ presumably reflects how much an ‘average listener’ can decode from the speech signal. Given the variability between listeners, this requires input from a panel of listeners [11]. And to include not only expert listeners (such as SLPs) in assessments, task instructions need to be understood without prior training. Furthermore, evaluation methods that allow real-time collection of responses may be preferred over those that require, for example, listeners transcribing what they perceive. In our research, we have introduced Audience Response Systems (ARS)-based assessments as a window into listeners’ perception of disordered speech. The ARS-based method allows intuitive task instructions and real-time response collection, thus meeting at least some desirable methodological features. We have used the ARS-based method in assessments of voice [12], and in assessments of speech produced by children with speech sound disorders [13], [14], with listener panels including experts (SLPs), lay adults, and children. We found no systematic differences between experts and lay listeners in their evaluations of intelligibility; at least in this task, SLPs seem to be representative of other listeners [13].
The ARS-based method has also served as a window into listeners’ evaluation of acceptability, that is, the perceived “differentness” of children’s way of speaking. Just like reduced intelligibility, reduced acceptability is a threat to successful communication for children with speech disorders [14]. Compared to intelligibility, however, acceptability is considerably less studied. The ARS-based method allowed us to investigate acceptability and intelligibility in parallel, and to compare the two constructs with reference to the same continuous scale. As expected, listeners reacted more frequently to speech sounding ‘awkward’ than to not understanding the spoken message [14]. In terms of listener differences, children appeared less critical in their evaluations than the adult listeners [14].
To conclude, developmental norms of children’s articulation and intelligibility are important when identifying children in need of clinical intervention. However, documentation underlying norms often obscures detail. Also, norms depend on who gets to set the boundary between ‘correct’ and ‘incorrect’, and between ‘intelligible’ and ‘unintelligible’. As such, developmental norms should be handled with care.
Developmental Language Disorder (DLD) is common in children, and can have long-term consequences for academic achievement and psychosocial well-being [15]. Identifying DLD during preschool years can therefore be important for mitigating an adverse developmental trajectory. For that purpose, comparing observed language in a child to developmental norms concerning for example vocabulary and grammar is important. But similarly to developmental norms concerning speech, norms concerning language depend on who sets the norms. Also, their insensitivity to detail makes existing norms ill-fit for tracking potential progress in children with limited verbal language, such as in children with DLD.
In our research group, we are exploring multimodal language-sample analysis as a way of tracking language development in children with severe DLD. For these children, intervention is often not limited to strengthening verbal language, but also aims to encourage communication via alternative means, like gestures, manual sign and/or pictures. I will present an insight into our ongoing work, as a case in point illustrating the value of sensitivity to more fine-grained aspects than ‘correct’/’incorrect’.
Finally, I hope to encourage reflection concerning the seeming dissonance between the measures we use, and what actually matters for children with speech/language disorders and their families. When asked what their preferred outcomes of intervention are, children themselves rarely mention consonants or grammatical inflections, but rather aspects like having fun with friends, being listened to, and not being teased [16]. And parents raise aspects like social inclusion, friendship and independence [16]. To clinicians, these perspectives are probably very familiar, but as researchers, we might need to remind ourselves of the potential gap between the topics we study and what impact they have in the lives of children with speech/language disorders.
Re-evaluation of historical SLP practices and attitudes sheds light on cultural biases against marginalized groups [17], calling previously held truths about what is ‘normal’ and what is ‘abnormal’ into question. As active in the field of children’s speech/language disorders, relying on norms based on decisions of what is ‘correct’ and what is ‘incorrect’, we should at least expose ourselves to such perspectives, and ask ourselves whose perspective we represent and why.
[1] D. K. Oller, R. E. Eilers, A. R. Neal, and A. B. Cobo-Lewis, ‘Late onset canonical babbling: a possible early marker of abnormal development’, Am J Ment Retard, vol. 103, no. 3, pp. 249–263, Nov. 1998, doi: 10.1016/s0021-9924(99)00013-1.
[2] J. M. Rudolph and L. B. Leonard, ‘Early Language Milestones and Specific Language Impairment’, Journal of Early Intervention, vol. 38, no. 1, pp. 41–58, Mar. 2016, doi: 10.1177/1053815116633861.
[3] A. Lohmander, I. Lundeborg, and C. Persson, ‘SVANTE – The Swedish Articulation and Nasality Test – Normative data and a minimum standard set for cross-linguistic comparison’, Clinical Linguistics & Phonetics, vol. 31, no. 2, pp. 137–154, Feb. 2017, doi: 10.1080/02699206.2016.1205666.
[4] S. Strömbergsson, G. Salvi, and D. House, ‘Acoustic and perceptual evaluation of category goodness of /t/ and /k/ in typical and misarticulated children’s speech’, The Journal of the Acoustical Society of America, vol. 137, no. 6, pp. 3422–3435, Jun. 2015, doi: 10.1121/1.4921033.
[5] B. Munson, J. Edwards, S. Schellinger, M. E. Beckman, and M. K. Meyer, ‘Deconstructing Phonetic Transcription: Covert Contrast, Perceptual Bias, and an Extraterrestrial View of Vox Humana’, Clin Linguist Phon, vol. 24, no. 4–5, pp. 245–260, Jan. 2010, doi: 10.3109/02699200903532524.
[6] S. McLeod, ‘Intelligibility in Context Scale: cross-linguistic use, validity, and reliability’, Speech, Language and Hearing, vol. 23, no. 1, pp. 9–16, Jan. 2020, doi: 10.1080/2050571X.2020.1718837.
[7] T. B. Lagerberg, E. Anrep‐Nordin, H. Emanuelsson, and S. Strömbergsson, ‘Parent rating of intelligibility: A discussion of the construct validity of the Intelligibility in Context Scale (ICS) and normative data of the Swedish version of the ICS’, International Journal of Language & Communication Disorders, vol. 56, no. 4, pp. 873–886, Jul. 2021, doi: 10.1111/1460-6984.12634.
[8] D. O’Leary, A. Lee, C. O’Toole, and F. Gibbon, ‘Intelligibility in Down syndrome: Effect of measurement method and listener experience’, International Journal of Language & Communication Disorders, vol. 56, no. 3, pp. 501–511, 2021, doi: 10.1111/1460-6984.12602.
[9] T. B. Lagerberg, J. Lam, R. Olsson, Å. Abelin, and S. Strömbergsson, ‘Intelligibility of Children With Speech Sound Disorders Evaluated by Listeners With Swedish as a Second Language’, Journal of Speech, Language, and Hearing Research, vol. 62, no. 10, pp. 3714–3727, Oct. 2019, doi: 10.1044/2019_JSLHR-S-18-0492.
[10] N. Miller, ‘Measuring up to speech intelligibility’, International Journal of Language & Communication Disorders, vol. 48, no. 6, pp. 601–612, 2013, doi: 10.1111/1460-6984.12061.
[11] T. B. Lagerberg, K. Holm, A. McAllister, and S. Strömbergsson, ‘Measuring intelligibility in spontaneous speech using syllables perceived as understood’, Journal of Communication Disorders, vol. 92, p. 106108, Jul. 2021, doi: 10.1016/j.jcomdis.2021.106108.
[12] K. Johansson, S. Strömbergsson, C. Robieux, and A. McAllister, ‘Perceptual Detection of Subtle Dysphonic Traits in Individuals with Cervical Spinal Cord Injury Using an Audience Response Systems Approach’, Journal of Voice, vol. 31, no. 1, p. 126.e7-126.e17, 2017, doi: 10.1016/j.jvoice.2015.12.015.
[13] S. Strömbergsson, K. Holm, J. Edlund, T. B. Lagerberg, and A. McAllister, ‘Audience Response System-Based Evaluation of Intelligibility of Children’s Connected Speech – Validity, Reliability and Listener Differences’, Journal of Communication Disorders, vol. 87, p. 106037, Sep. 2020, doi: 10.1016/j.jcomdis.2020.106037.
[14] S. Strömbergsson, J. Edlund, A. McAllister, and T. B. Lagerberg, ‘Understanding acceptability of disordered speech through Audience Response Systems-based evaluation’, Speech Communication, vol. 131, pp. 13–22, Jul. 2021, doi: 10.1016/j.specom.2021.05.005.
[15] D. V. M. Bishop, M. J. Snowling, P. A. Thompson, and T. Greenhalgh, ‘Phase 2 of CATALISE: a multinational and multidisciplinary Delphi consensus study of problems with language development: Terminology’, Journal of Child Psychology and Psychiatry, vol. 58, no. 10, pp. 1068–1080, 2017, doi: 10.1111/jcpp.12721.
[16] S. Roulstone, J. Coad, A. Ayre, H. Hambly, and G. Lindsay, ‘The preferred outcomes of children with speech, language and communication needs and their parents’, Department for Education, London, UK, DFE-RR247-BCRP12, Dec. 2012. Accessed: Apr. 23, 2020. [Online]. Available: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/219625/DFE-RR247-BCRP12.pdf
[17] J. F. Duchan and L. E. Hewitt, ‘How the Charter Members of ASHA Responded to the Social and Political Circumstances of Their Time’, American Journal of Speech-Language Pathology, doi: 10.1044/2022_AJSLP-22-00273.
Kirsty McDougall (University of Cambridge)
1 October 2024, 9:30, University of Tartu Main Building, Ülikooli 18. Recording of the presentation is available online
Perturbations of the flow of a speaker’s speech such as filled and silent pauses, repetitions, self-interruptions and sound prolongations occur with relatively high prevalence in the speech of people who stutter (‘dysfluency’). They are also present to differing extents in the spontaneous speech of normally-fluent speakers (‘disfluency’) (e.g. [7]), yet the speaker-specificity of such features has received little attention in phonetic research. Aspects of speech such as filled and silent pausing may play a part in the planning of speech (e.g. [2]) and therefore may be influenced by psycho- or socio-linguistic demands, thus they have strong potential for individual variation. Other breaks in fluency such as repetition, prolongation or self-interruptions might also function as part of the speech planning process and be difficult to control consciously, thus offering a further source of individual variation.
Analysis of individuals’ use of disfluencies has great potential for application in forensic speaker comparison cases, in which voice recordings each of an unknown speaker committing a crime and of a suspect are compared with a view to assessing the likelihood that the same speaker is on both recordings. The bulk of the literature investigating speaker-distinguishing properties of phonetic features for forensic applications has focussed on variables which bear a direct relationship with a speaker’s anatomy, for example fundamental frequency which reflects the length and mass of a speaker’s vocal folds, or formant frequencies which reflect the dimensions and configuration of the vocal tract (see e.g. [1]). Investigating the speaker-distinguishing potential of disfluency features focusses on a very different aspect of a speaker’s performance: speech features which are behavioural rather than anatomical. As well as the phonetic theoretical reasons for investigating the speaker-specificity of disfluency features, these features are largely realised through the temporal domain and therefore generally well-preserved in the poor recording conditions of forensic cases where background noise and telephone transmission (with its reduced bandwidth) are typical. This is in contrast to the ‘anatomical’ features mentioned above which are conveyed through spectral (frequency) information for which adverse recording conditions are more problematic.
This talk will present findings from an ongoing programme of research by McDougall and Duckworth into individual variation in fluency behaviour and its application in forensic speaker comparison casework. The TOFFA framework ‘Taxonomy of Fluency features for Forensic Analysis’ devised by McDougall and Duckworth [3, 4] for quantifying individual differences in disfluency will be outlined and results from studies applying TOFFA to a number of forensically relevant datasets will be presented, considering the effects of important factors such as speaking style and (lack of) contemporaneity of recording session, as well as variation across different accents of a language (e.g. [5]).
The talk will also illustrate the application of TOFFA to forensic casework practice, using a number of example cases where analysis of disfluencies was of key importance. These cases come out of collaborative work conducted with J.P. French Associates, United Kingdom, a forensic phonetic consultancy where the TOFFA framework has been applied to characterize disfluency usage in forensic speaker comparison cases for a number of years [6]. Ongoing practical issues and directions for further research will be outlined.
The talk will conclude that when it can be implemented, systematic disfluency analysis is a valuable tool in the forensic phonetician’s toolkit, and one which complements other types of analysis well.
The author is grateful to her collaborators Peter French, Toby Hudson, Christin Kirchhübel, Debbie Loakes, Alice Paver, Richard Rhodes who have all contributed to this work in various ways, and especially to Martin Duckworth for his inspiration to start this line of research and his close involvement with this research from its inception many years ago to current developments.
[1] P. Foulkes and P. French, “’Application of the ‘TOFFA’ framework to the analysis of disfluencies in forensic phonetic casework,” in The Oxford Handbook of Language and Law, P. M. Tiersma and L. M. Solan, Eds. Oxford: Oxford University Press, 2012, pp. 557-572.
[2] F. Goldman-Eisler, Psycholinguistics: Experiments in Spontaneous Speech. London: Academic Press, 1968.
[3] K. McDougall and M. Duckworth, “Profiling fluency: an analysis of individual variation in disfluencies in adult males,” Speech Communication, vol. 95, pp. 16-27, 2017.
[4] K. McDougall and M. Duckworth, “Individual patterns of disfluency across speaking styles: a forensic phonetic investigation of Standard Southern British English,” International Journal of Speech Language and the Law, vol. 25(2), pp. 205-30, 2018.
[5] K. McDougall, M. Duckworth and T. Hudson, “Individual and group variation in disfluency features: a cross-accent investigation,” Proceedings of the 18th International Congress of Phonetic Sciences, Glasgow, Australia, Paper number 0308, August 2015.
[6] K. McDougall, R. Rhodes, M. Duckworth, P. French, and C. Kirchhübel, “Application of the ‘TOFFA’ framework to the analysis of disfluencies in forensic phonetic casework,” Proceedings of the 19th International Congress of Phonetic Sciences, Melbourne, Australia, pp. 731-735, August 2019.
[7] E. Shriberg, “To ‘errrr’ is human: ecology and acoustics of speech disfluencies,” Journal of the International Phonetic Association, vol. 31, pp. 153-69, 2001.
Adrian Simpson (Friedrich Schiller University Jena)
1 October 2024, 16:30, University of Tartu Main Building, Ülikooli 18. Recording of the presentation is available online
When asked to identify the gender of stimuli from a randomly chosen sample of adult speakers, listeners make judgments that agree almost 100% with the self-reported gender of the speakers. Many of the acoustic correlates responsible for these systematic and consistent judgments can initially be attributed to sex-specific biological differences that arise during puberty. Longer and thicker male vocal folds produce an average fundamental frequency that is typically half that of the female value [1]. Disproportionate lowering of the larynx produces a longer male vocal tract giving rise to formant frequencies that are lower than those produced in an average female vocal tract. Despite the acoustic consequences of these average biological differences, it is also clear that the magnitude and form of the acoustic differences are in part attributable to socio-culturally acquired patterns. This is apparent from intercultural differences in the magnitude and non-uniformity of gender-specific differences [2, 3, 4]. Likewise, long-term studies have found marked reductions in female fundamental frequency over an interval of several decades, indicating changes in voice accompanying changes in gender role [5]. However, the most intriguing example of learnt gender-specific patterns is the vocal expression of gender in prepubertal voices. Any anatomical differences prior to the onset of puberty are negligible [6]. Nevertheless, gender identification of prepubertal sentence-length stimuli is still above-chance, typically at around 70%. However, this figure belies a more complex picture, in which the gender identification of some speakers remains at chance level, while for others listeners’ ratings approach those found for adult speakers [7]. This suggests that some children are producing a consistent and robust set of acoustic correlates that listeners use to decode a child’s gender.
This talk will examine the difficulty of teasing apart nature and nurture when accounting for gender-specific differences in adult and prepubertal voices. We will consider the importance of providing a differentiated picture of a speaker’s gender, gender identity and gender role [8, 9]. Finally, we will look at ways of identifying the acoustic correlates that produce systematic gender ratings in children’s voices.
[1] Stevens, Kenneth N. 1998. Acoustic Phonetics. Massachusetts: M.I.T. Press.
[2] Fant, Gunnar. 1975. Non-uniform vowel normalization. STL-QPSR 2–3, 1–19.
[3] Henton, Caroline G. 1995. Cross-language variation in the vowels of female and male speakers. In Proc. XIIIth ICPhS, vol. 4. Stockholm, 420–423.
[4] Traunmüller, Hartmut & Anders Eriksson. 1993. The frequency range of the voice fundamental in the speech of male and female adults. Unpublished ms. Stockholm.
[5] Pemberton, Cecilia, Paul McCormack, & Alison Russell. 1998. Have women’s voices lowered across time? A cross sectional study of Australian women’s voices. Journal of Voice 12(2), 208–213.
[6] Fitch, W. Tecumseh & Jay Giedd. 1999. Morphology and development of the human vocal tract: A study using magnetic resonance imaging. Journal of the Acoustical Society of America 106(3), 1511–1522.
[7] Funk, Riccarda & Adrian P. Simpson. 2023. The acoustic and perceptual correlates of gender in children’s voices. Journal of Speech, Language and Hearing Research , 1–18.
[8] Weirich, Melanie & Adrian P. Simpson. 2018. Gender identity is indexed and perceived in speech. PLoS ONE 13(12), e0209226.
[9] Weirich, Melanie & Adrian P. Simpson. 2019. Effects of gender, parental role and time on infant- and adult-directed read and spontaneous speech. Journal of Speech, Language and Hearing Research 62(11), 4001–4014.
Hands-on workshops
Claire Nance & Sam Kirkham (Lancaster University) – slides
2 October 2024, 10:00, University of Tartu Main Building, Ülikooli 18
In this workshop we will introduce participants to using ultrasound tongue imaging for phonetic research. Ultrasound provides a (relatively) easy method of viewing the tongue in two dimensions for articulatory research. Most commonly, video is recorded of the tongue in midsagittal position (Fig. 1). The best image is obtained from the surface of the tongue and typically researchers extract the coordinates of the midsagittal tongue surface for comparison within and across speakers. Typically, the image is oriented such that the tongue root is on the left and the tongue tip on the right.
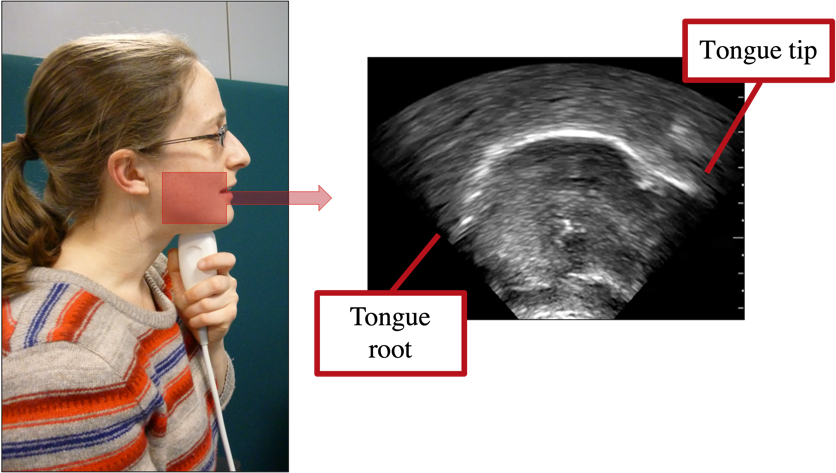
Fig 1. Example of the view typically obtained from ultrasound tongue imaging in phonetic research.
We will work with workshop participants on two ultrasound machines to demonstrate the equipment and explain a basic workflow which could be used for a small research project, developing teaching resources, or in public engagement work. First, we will discuss what kind of research questions ultrasound analysis can answer and give some examples from when we have used ultrasound in teaching, public engagement, and research. Then, we will introduce participants to the software now most commonly used for recording ultrasound data, Articulate Assistant Advanced (AAA) [1]. We will explain how to obtain the best images for research purposes and workshop participants will make some recordings in AAA. To explain the initial stages of data analysis, we will demonstrate how to label audio data recorded in AAA, fit splines to ultrasound tongue images, and export spline coordinates for further analysis. Finally, we will show workshop participants how to extract videos from ultrasound data for teaching, demonstrations, and knowledge exchange.
Ultrasound is a practical and relatively cheap option for collecting articulatory phonetic data. The probe is placed under a participant’s chin making it less invasive than, for example, EMA, and no calibration process is required. These advantages can make ultrasound an attractive option for research in this area. Typically, it is easier and more fruitful to be able to make within-speaker comparisons of sounds which are easily differentiated by different tongues shapes in the midsagittal dimension, for example, advanced and retracted tongue root vowels [2], liquid consonants across languages in the same speakers [3], or palatalised and non-palatalised consonants [4]. We will also give some tips on using ultrasound for teaching, demonstrations, and public engagement, with examples from our own experience e.g. [5]. Ultrasound tongue imaging can also be combined with lip camera images, although this won’t be covered in our workshop.
In this workshop we will use the hardware setup recommended for research by Articulate Instruments Ltd (see their webpage). This includes the Telemed MicrUS ultrasound machine, Convex 2-4MHz 20mm radius ultrasound probe, Pulse Stretch audio/ultrasound syncronisation unit, Ultrafit probe stabilisation headset [6], and microphone and sound cards options (Fig. 2). During the workshop we will record data in the software AAA [1], and conduct some initial analysis in Praat and AAA. Participants can work together on the laptops we will provide as the software requires a proprietary licence and only runs on Windows. If workshop participants have access to a AAA dongle and Windows laptop, they are welcome to download AAA and use their own devices.
We will first discuss how to best fit the headset on a range of research participants with different sized heads and hairstyles. Workshop participants will be able to practise on each other and we will advise on how to obtain the best images from participants with different anatomies. We will then demonstrate how to set up a small research project in AAA and record some data. We first recommend recording the occlusal plane for each participant, for example by using a bite plate [7]. We then suggest recording each research participant swallowing some water to obtain an image of the hard palate for reference. We will discuss optimal time and numbers of repetitions for recording stimuli from different participants, as well as settings for the ultrasound and recording.

Fig 2. Takayuki Nagamine recording ultrasound data with the Telemed MicrUS and Ultrafit headset.
Once we have recorded some data, we will then show workshop participants a simple workflow for data extraction and analysis. Workshop participants will learn how to obtain tongue surface coordinates based on acoustic landmarks. In order to do this, we will export audio from AAA, and then label in Praat [8]. We will then reimport Praat TextGrids into AAA so that acoustic events are labelled synchronous with ultrasound video. The coordinates of the tongue surface are obtained by automatically fitting splines to the data using the DeepLabCut plugin in AAA [9], [10]. We will then show workshop participants how to export the coordinates of the tongue splines rotated to each research participant’s occlusal plane.
Finally, we will demonstrate how workshop participants can export videos from their data for sharing with participants, embedding in research presentations, or using for teaching and public engagement. Videos can be exported of fitted tongue splines and/or the ultrasound image and audio. For examples of how we have used this kind of resource see this website (part of [11]).
[1] A. Wrench, Articulate Assistant Advanced (Version 221.2). Edinburgh: Articulate Instruments, 2023.
[2] S. Kirkham and C. Nance, ‘An acoustic-articulatory study of bilingual vowel production: Advanced tongue root vowels in Twi and tense/lax vowels in Ghanaian English’, J. Phon., vol. 62, pp. 65–81, 2017.
[3] T. Nagamine, ‘Dynamic tongue movements in L1 Japanese and L2 English liquids’, in Proceedings of the 20th International Congress of the Phonetic Sciences, R. Skarnitzl and J. Volín, Eds., Charles University, Prague: Guarant International, 2023, pp. 2442–2446.
[4] C. Nance and S. Kirkham, ‘Phonetic typology and articulatory constraints: The realisation of secondary articulations in Scottish Gaelic rhotics’, Language, vol. 98, no. 3, pp. 419–460, 2022.
[5] C. Nance et al., ‘Acoustic and articulatory characteristics of rhoticity in the North-West of England’, in Proceedings of the 20th International Congress of the Phonetic Sciences, R. Skarnitzl and J. Volín, Eds., Charles University, Prague: Guarant International, 2023, pp. 3573–3577.
[6] L. Spreafico, M. Pucher, and A. Matosova, ‘UltraFit: A Speaker-friendly Headset for Ultrasound Recordings in Speech Science’, in Interspeech 2018, 2018. doi: 10.21437/interspeech.2018-995.
[7] J. M. Scobbie, E. Lawson, S. Cowen, J. Cleland, and A. Wrench, ‘A common co-ordinate system for mid-sagittal articulatory measurement’, QMU CASL Work. Pap., vol. 20, 2011.
[8] P. Boersma and D. Weenik, ‘Praat: doing phonetics by computer [Computer program]. Version 6.4.01’. Accessed: Nov. 30, 2023. [Online]. Available: http://www.praat.org/
[9] A. Mathis et al., ‘DeepLabCut: markerless pose estimation of user-defined body parts with deep learning’, Nat. Neurosci., vol. 21, no. 9, pp. 1281–1289, 2018, doi: 10.1038/s41593-018-0209-y.
[10] A. Wrench and J. Balch-Tomes, ‘Beyond the Edge: Markerless Pose Estimation of Speech Articulators from Ultrasound and Camera Images Using DeepLabCut’, Sensors, vol. 22, no. 3, p. 1133, 2022, doi: 10.3390/s22031133.
[11] E. Lawson, J. Stuart-Smith, J. Scobbie, and S. Nakai, ‘Seeing Speech: An articulatory web resource for the study of Phonetics.’ Accessed: Aug. 23, 2023. [Online]. Available: https://seeingspeech.ac.uk
Stefan Werner (University of Turku)
2 October 2024, 14:00, University of Tartu Main Building, Ülikooli 18
This workshop is targeted at researchers with no previous experience in using PsychoPy [1] or PsychoJS [2]; familiarity with Praat’s multiple forced choice listening experiments may be helpful but is also not required. Having attended the workshop, participants should be able to design, implement and run simple phonetic experiments both on a local computer and via the World Wide Web. The workshop’s three-hour time limit is behind the “simple” experiment constraint; nevertheless, the acquired basic PsychoPy/PsychoJS competency should also help participants with working independently towards more sophisticated setups later.
The first part of the workshop will introduce participants to the basic workings of PsychoPy. Since 2002, this open-source program has been widely used for behavioral experiments in, above all, psychology and psycholinguistics, but less so in phonetics, despite the fact that recent versions offer comprehensive audio processing functionality. PsychoPy is much more versatile and adaptable than Praat’s ExperimentMFC or demo window and, at the same time, easier to use and more comprehensively documented.
PsychoPy provides two different environments for designing experiments, the visual BUILDER and the text-based CODER. Whilst the CODER makes possible an even larger variety of experimental setups than the BUILDER it also comes with a steeper learning curve, especially for users without prior exposure to Python programming. Thus, in our workshop we will concentrate on the BUILDER to construct a phonetic experiment.
In the second part of the workshop we will find out how to adapt this experiment to online use, gathering data from subjects via the internet. This is made possible by PsychoJS, the online variant of PsychoPy. JS stands for JavaScript, the programming language most often used in web applications executed in your browser – but again, workshop participants will not be required to learn how to write programming language code. Instead, PsychoPy’s graphical BUILDER tool can also be used to produce the necessary JavaScript and HTML code.
[1] PsychoPy https://psychopy.org/
[2] PsychoJS https://github.com/psychopy/psychojs