Masintõlke toimetamine
Masintõlke toimetamine
Masintõlke peale mõeldes tulevad üldjuhul meelde populaarsed masintõlketeenused nagu Google Translate ehk Google’i tõlge. Samuti kipuvad masintõlkega seostuma eelkõige mingil viisil vigased ja/või nalja pakkuvad tõlkelaused ning -tekstid. Kuigi idee kasutada arvuteid keele tõlkimiseks ulatub juba 1940. aastatesse ning selle uurimine on pika ajalooga, ei ole siiani täidetud eesmärki saavutada automaatne tõlkimine, mis oleks veatu ja igasuguste piiranguteta. Viimastel aastatel on aga tehisnärvivõrkudel põhinev masintõlketehnoloogia hüppeliselt parandanud tõlgete kvaliteeti nii, et automaatselt tõlgitud laused võivad nii mõnigi kord olla täiesti veatud või esmapilgul märkamatuks jäävate vigadega. Koos masintõlketehnoloogia arenguga on muutunud ka probleemid, mis sellise tehnoloogia kasutamisel tõenäoliselt tekkida võivad, mistõttu on masintõlgitud tekstiga töötamisel kasulik teada ka üht-teist kõnealuse tehnoloogia ajaloost ning uusimatest arengusuundadest. Seni toimunud arengu ajajoonel võib masintõlkesüsteemid jaotada kolme peamisse kategooriasse.
Reeglipõhine masintõlge
Tavapäraselt nimetatakse masintõlke ajalugu käsitledes esimesena lingvistilistel teadmistel põhinevaid ehk reeglipõhiseid masintõlkesüsteeme (ingl. Rules Based Machine Translation (RBMT)). Nende süsteemide jaoks on vaja mahukaid käsitsi koostatud grammatikaid ning põhjalikke leksikone, mis hõlmavad morfoloogilist, süntaktilist ja semantilist informatsiooni, mistõttu on taoliste süsteemide jaoks vajalike vahendite loomine kulukas ning väga töö- ja ajamahukas (Liin, Muischnek, Müürisep, Vider 2012: 21). Samas seisneb reeglipõhise masintõlkesüsteemi tugevus selles, et ilmnevaid vigu saab juba koostatud reeglite muutmisega hõlpsasti parandada. Vigade parandamine on süstemaatiline ja ekspertidel on täpsem kontroll selle üle, kuidas keelt süsteemis töödeldakse (ibid. 8). Kokkuvõttes võib aga öelda, et taoliste süsteemide hea kvaliteedi ja laialdase kasutuselevõtu peamine takistus on siiski liiga suur aja- ja ressursikulu. Kuigi teatavate eesmärkide jaoks võivad reeglipõhised masintõlkesüsteemid olla piisavalt head, on reeglipõhise käsitluse puhul tõeliselt tõhusa masintõlkesüsteemi loomine välistatud peamiselt kahel põhjusel: vajalike andmete sisestamine on põhimõtteliselt lõpmatu ülesanne ning pealegi ei ole võimalik täpselt määratleda kogu teadmiste hulka, mida masintõlkesüsteem parimaks toimimiseks vajaks (Poibeau 2017: 252).
Statistiline masintõlge
Koos arvutusvõimsuse kasvuga ja interneti laialdase kasutuselevõtuga muutus võimalikuks ka suurte andmehulkade abil masintõlkesüsteemide n-ö automaatne treenimine. Arendama hakati süsteeme, mis piisava hulga olemasolevate paraleeltekstide alusel genereerivad automaatselt masinõppe abil lähteteksti tõenäoliselt ligilähedase tõlke. Statistilise masintõlke (ingl. Statistical Machine Translation (SMT)) puhul luuaksegi tõlked kakskeelsetele korpustele tuginevate statistiliste mudelite abil. Selline masintõlge vajab korralikult toimimiseks miljoneid näitelauseid (Liin et al. 2012: 8), samas on taolise süsteemi loomiseks vaja vähem inimtööjõudu kui reeglipõhise masintõlke puhul, sest statistilise masintõlkesüsteemi treenimiseks kasutatakse juba olemas olevaid tekste.
Tehisneurovõrkudel põhinev masintõlge
Viimastel aastatel on masintõlketehnoloogias esile kerkinud uus tehnoloogia, mis algupäraselt oli inspireeritud inimaju närvivõrkude talitlusest. Tehisnärvivõrkudel põhinevad masintõlkesüsteemid (ingl. Neural Machine Translation (NMT)) suudavad luua keerukamaid kontseptsioone hierarhiliselt esitatud informatsioonikihtidest ning on võimelised süsteemile ette antud andmekogudest õppima ja seeläbi tõlkimises paremaks muutuma, mis tähendab, et selline süsteem vajab inimesepoolset juhendamist ja sekkumist märksa vähem.
NMT on SMT edasiarendus sellest vaatenurgast, et NMT on tegelikult samuti korpuspõhine masintõlge ja ka NMT-tehnoloogial põhinevat masintõlkesüsteemi on vaja suurte olemasolevate andmekogude abil n-ö treenida, misläbi süsteem hakkab masinõppe toel tekste paremini tõlkima, aga NMT põhineb uudsel tehnoloogial: tehisnärvivõrkudel. Tehisnärvivõrkudel põhinev tehnoloogia tähendab lihtsustatult hulka tehisneuroneid, mis on omavahel seotud ning millest ühed neuronid saavad teistelt neuronitelt sisendi, teevad seejärel teatavad arvutused ning annavad siis väljundi. Tehisneuronite vahelistel ühendustel on aga erinevad kaalud, millest oleneb, kui palju üks või teine neuron ülejäänud neuroneid ja seega ka lõplikku väljundit ehk tulemust mõjutab. Lisaks on keeleline mitmekesisus NMT puhul esitatud vektoritena ehk matemaatiliste suurustena, mida võiks võrrelda geograafiliste koordinaatidega, mille abil määratakse üksteisega seotud või üksteisest kaugel asuvad mõisted (Forcada 2017). See võimaldab NMT-l paremini tõlkida lauset kui tervikut, luues sobivad seosed ka lauses üksteisest kaugele jäävate fraaside vahel. Tulemuseks on grammatiliselt korrektsem ja palju ladusam tekst kui traditsioonilise SMT puhul, kuigi samal ajal võivad sihtteksti tekkida siiski sisulised vead (vt jaotist „Tüüpvead“ allpool).
Tehisneurovõrkudel põhinev masintõlge on tihedalt seotud tehisintellekti ja masinõppe arenguga üldiselt ning annab praegu kõige parema tulemuse eelkõige olukorras, kus masintõlkesüsteemi treenitakse kitsa valdkonna olemasolevate andmekogudega (tekstidega). Kokkuvõtteks võib isegi öelda, et kuna viimasel paaril aastal on tänu NMT tehnoloogiale masintõlke valdkonnas toimunud niivõrd kiire ja ulatuslik areng, ei ole masintõlke kaugem ajalugu enam niivõrd asjakohane ning nüüdseks keskendutakse peamiselt NMT uurimisele, arendamisele ja parendamisele (Nieminen 2020).
Lisaks tõlkimisele võib tehisneurovõrkudel põhinev masintõlkesüsteem suuta lahendada ka muid ülesandeid. Näiteks suudab Tartu Ülikoolis arendatav NMT-süsteem parandada õigekeelsusvigu, kui kasutaja peaks sisestama lähtekeelse teksti vigases keeles (sest see masintõlkesüsteem on õppinud väljundit genereerima ainult korrektse keele näidete abil), ning kohendada stiili samas keeles, muutes kas kõnekeelse teksti viisakaks tekstiks või vastupidi (Fišel 2020).
Hübriidsüsteemid
Masintõlkesüsteemide puhul võidakse kasutada ka n-ö hübriidlahendusi, mis kombineerivad eespool kirjeldatud tehnoloogiaid. Näiteks on 2012. aastal ilmunud väljaandes „Eesti keel digiajastul“ (Liin et al. 2012: 8) märgitud, et kuna „statistiliste ja reeglipõhiste süsteemide plussid ja miinused kalduvad teineteist täiendama, siis uuemad uurimused keskenduvad neid lähenemisi kombineerivatele hübriidsüsteemidele“. Kuigi ka neuromasintõlkesüsteemid tõlkisid esialgu hästi üksnes lühemaid lauseid ning pikemate ja keerukamate lausete puhul olid statistilise masintõlke süsteemid paremad, on nüüdseks leitud lahendused, mis võimaldavad tõhusalt rakendada ka ainult NMT-tehnoloogial põhinevaid süsteeme (Poibeau 2017: 190).
Kuigi masintõlke kvaliteet on viimastel aastatel tänu tehisneurovõrkudel põhinevale tehnoloogiale märkimisväärselt paranenud, ei ole masintõlgitud tekstid üldiselt siiski sellisel tasemel, et neid oleks võimalik kohe avaldada. Erandlikud juhud on võimalikud siis, kui masintõlget rakendatakse kitsalt väga spetsiifilises valdkonnas, kus parimate tulemuste saavutamiseks rakendatakse hõlpsamini masintöödeldavat piiratud keelt (vt jaotist „Masintõlke eeltoimetamine“ allpool) ning konkreetse valdkonna jaoks loodud masintõlkesüsteemi (Koponen 2016: 132).
Kõige olulisem on meeles pidada seda, et masintõlkesüsteem ei saa tõlgitava teksti sisust aru, nagu inimesed keeles väljendatust aru saavad. Kõik praegu kasutatavad tehisintellekti rakendusviisid, sealhulgas keeletehnoloogilised rakendused nagu masintõlge, kuuluvad kitsa tehisintellekti hulka (ingl artificial narrow intelligence, ANI), mis tegeleb üksnes ühe väga konkreetselt piiritletud ülesandega ega oska sellest kaugemale „mõelda“ (Fišel 2020). Üldine tehisintellekt (ingl artificial general intelligence, AGI) viitab masinale, mis suudab täita igasugust intellektuaalset ülesannet ja praegu on see siiski ulmekirjanduse pärusmaa (vt kursust „Elements of AI“, III. „Tehisintellekti filosoofia“).
Masintõlkesüsteemide kvaliteedi hindamise viisid võib üldjoontes jagada kahte järgmisse kategooriasse: automaatsed hindamismeetrikad ja inimeste abil hindamine. Kuigi inimesepoolne hindamine võib olla ühest küljest kõige tõhusam ja laiahaardelisem, on see töö- ja ajamahukas ning kannab endas alati teatavat subjektiivsuse riski. Automaatseid meetrikaid ehk hindamismõõdikuid on palju, tuntumat neist on näiteks BLEU, METEOR, NIST, TER, CharCut. Mõned neist (nt BLEU ja METEOR) võrdlevad masina tõlgitud teksti ja inimese tõlgitud teksti, teised (nt TER, CharCut) aga masina tõlgitud teksti ning selle sama masintõlgitud teksti järeltoimetatud versiooni ehk lõpliku tulemuse saamiseks vajalike muudatuste arvu. Esimesel juhul mõõdetakse seda, kuivõrd kattub masintõlge inimtõlkega. Teisel juhul vaadatakse seda, kuivõrd on inimesel vaja masintõlgitud teksti muuta, et saada sellest lõplik, vigadeta tekst. Inimesepoolne kvaliteedi hindamine on märksa mitmekülgsem ja hõlmab näiteks seda, kuivõrd hästi on edasi antud teksti tähendus või kui ladus tekst on, kuid nende omaduste määramisega kaasneb ka subjektiivsus. Samas ei tähenda see, et automaatsed hindamismeetodid oleksid veatud ja tingimata täpsemad, sest need ei pruugi toime tulla keelelise varieeruvusega. Näiteks BLEU puhul on leitud, et see ei ole alati korrelatsioonis inimeste poolt antud hinnangutega (Callison-Burch, Osborne, Koehn 2006). Lõpliku teksti saamiseks masintõlkesse tehtavate vajalike muudatuste arvul (kasutatakse ka terminit ‘toimetamiskaugus‘, ingl edit distance) põhinevaid mõõdikuid on kritiseeritud kahel põhjusel: 1) suurem masintõlkes tehtavate muudatuste arv ei tähenda alati, et masintõlge on halvem; 2) toimetamist (nagu ka tõlkimist) ja selle tasustamist ei saa taandada üksnes klahvivajutuste arvule, sest toimetaja töö hõlmab teksti sisulise õigsuse kontrollimist (mida on tegevusena märksa keerulisem mõõta), mitte üksnes tähemärkide sisestamist või kustutamist (vt näiteks Iizuka 2019).
Kuna igal hindamismeetodil on oma plussid ja miinused, rakendatakse masintõlkesüsteemide kvaliteedi hindamiseks üldjuhul eri meetodite kombinatsioone.
Ettevõte Tilde pakub oma veebisaidil võimalust mõõta masintõlgitud tekstide BLEU-skoori: https://www.letsmt.eu/Bleu.aspx.
Välja töötada püütakse ka uusi hindamissüsteeme, mis oleksid usaldusväärsemad, näiteks BERTScore.
Masintõlke muudab keeruliseks ja vigaderohkeks eelkõige asjaolu, et keeruline on üheselt defineerida seda, mida tähendab tõlkimine. Samuti pole lihtne täpselt määratleda seda, kuidas piiritleda millegi tähendust ja kuidas olla kindel, et tähendus on edasi antud. Kui püüame ühes keeles väljendatud mõtet teise keelde üle kanda, tekib palju küsimusi, mis ei ole seotud üksnes keeleteadusega, vaid ka psühholoogiaga ja isegi filosoofiaga: kas tõlge peaks põhinema sõnadel, fraasidel või lausetel; kuidas üldse millegi tähendust kindlaks teha ja kas kõik saavad sellest tähendusest ühtmoodi aru (Poibeau 2017: 8)?
Üldistatult on masintõlkes tekkivad vead seotud konkreetse masintõlkesüsteemi tehnoloogiaga. Statistilistele masintõlkesüsteemidele on iseloomulikud ühesugused tüüpvead, tehisneurovõrkudel põhinevatele masintõlkesüsteemidele teistsugused tüüpvead. See tähendab, et masintõlkes tekkivad vead on mõnevõrra ennustatavad, mis muudab teatavatest tüüpvigadest teadliku järeltoimetaja jaoks ka masintõlgitud tekstide toimetamise hõlpsamaks.
SMT ja NMT süsteemide puhul esinevad teatavatel juhtudel ühesugused tüüpvead, nagu näiteks ebaühtlus numbrite ja URL-ide ning terminoloogia ülekandmises ja pärisnimede valeks tõlkimine, kuid NMT puhul on tavapärasemad semantilist laadi vead ning loomingulisem masintõlkimine ja isegi uute sõnade leiutamine (Forcada 2017).
SMT puhul võib masintõlkes oodata veel selliseid tavapäraseid vigu nagu täiesti tõlkimata jäänud sõnad, tõlkesse lisandunud või sealt puudu olevad sõnad, süntaksi ja sõnajärjega ning grammatikaga seotud probleemid.
NMT annab varasematest tehnoloogiatest märkimisväärselt parema tulemuse ka selliste keelte puhul, millel on näiteks keerukam morfoloogia ja paindlik sõnade järjekord (nagu eesti keelel). NMT võtab paremini arvesse konteksti ning saab hakkama ka pikemate ja keerulisemate lausete tõlkimisega nii, et tihti on tulemus grammatiliselt veatu, sidus ja igati loogiline, mistõttu nimetatakse NMT peamise tugevusena tihtipeale sellest saadava masintõlgitud teksti ladusust (SDL plc 2018: 29-30). Ladus ja pealtnäha veatu teksti loomise võime on aga samal ajal ka NMT üks olulisimaid miinuseid masintõlke järeltoimetamise seisukohast, sest järeltoimetaja jaoks võib see olla väga petlik (ibid: 30). Ka Euroopa Komisjoni kirjaliku tõlke peadirektoraadi eesti keele osakonna tõlkija Ingrid Sibul jõudis 2017. aasta lõpus masintõlgitud tekste analüüsides järeldusele, et tehisnärvivõrkudel põhineva masintõlkega loodud tekstid „on grammatiliselt soravad, aga tähenduse poolest vähem usaldusväärsed“ (Sibul 2017: 5).
NMT-süsteemid on praegu kõige edukamad siis, kui need õpetatakse masinõppetehnoloogia abil välja kitsa valdkonna sarnaste tekstide alusel. See tähendab, et NMT ei ole kuigi edukas selliste sõnade/fraaside/tekstide tõlkimises, mida masintõlkesüsteem oma n-ö treeningu jooksul näinud ei ole. Kui SMT puhul oli tõenäoline, et süsteem kopeeris tundmatud sõnad ilma neid tõlkimata lähtekeelsest tekstist sihtkeelsesse teksti, siis NMT võib tundmatu lauseosa puhul lihtsalt korrata mingit juba süsteemile tuttavat sõna, sisestada tõlkesse hoopis asjassepuutumatu suvalise sõna või leiutada uue. Alloleval pildil on masintõlkeuurija Maarit Koponen oma Twitteri säutsus kirjeldanud, et kuigi ta ei ole päris nõus väitega, et NMT on tõlkimises väga inimese moodi, sisestas tema töö osaks olev NMT-süsteem tõlkesse täiesti ootamatult lähtetekstis mitte oleva tekstiosa „Ma ei tea, mida teha. Ma ei tea.“, mis kõlab nagu üks kõige inimlikumaid asju, mida teha.

Seniseid arengusuundi ja masintõlke analüüse arvesse võttes võib öelda, et inimene, kes kasutab või hakkab (lähi)tulevikus kasutama masintõlget näiteks oma töös, puutub kõige tõenäolisemalt kokku just tehisnärvivõrkudel põhineva süsteemiga ning kui see süsteem annab tõlkena igati veatuna tunduva väljundi, tuleks siiski tõlke sisulist õigsust hoolikalt kontrollida.
Üldiselt võib ka pealtnäha korrektses masintõlkes esineda siiski näiteks järgmisi vigu:
- vale tähendus või valed seosed (või ebasobiv sõnajärg);
- valed terminid;
- konteksti mitte arvesse võttev tõlge, näiteks ühe lause kaupa tõlkimine selliste üksteisele järgnevate lausete puhul nagu
„See on Helen. See on tema auto.“ – „This is Helen. This is his car.”
ja võrdluseks korrektne tõlge ühe lausena
„See on Helen, see on tema auto.“ – „This is Helen, this is her car.”
(Google Translate, 27.10.2020)
Mis masintõlkevigu põhjustab?
Masintõlkes tekkivate vigade põhjusi ei ole alati lihtne täpselt välja selgitada, kuid enamasti on need seotud masintõlkesüsteemi n-ö treenimiseks kasutatud tekstidega ehk treeningmaterjaliga (paralleelkorpustega). Kehv masintõlge võib olla seotud näiteks kas ebasobiva (vale valdkonna või liiga üldise) treeningmaterjaliga või süsteemi treenimiseks kasutatavate tekstide liiga väikese hulgaga. Nagu ka tõlkimise puhul, võib masintõlke väljundi halb kvaliteet olla seotud ka sisendi ehk lähteteksti halva kvaliteediga.
Tõlkevaldkonna mitme ühenduse (Elia, EMT, EUATC, FIT Europe, GALA ja LIND) koostöös loodud keeletööstuse ülevaatliku aruande Language Industry Survey 2019 kohaselt soovis aruande aluseks olevale küsitlusele vastanud tõlkevaldkonna (eelkõige suurematest) ettevõtetest 51% masintõlke rakendamist oma töös suurendada ning 18% ettevõtetest oli valmis masintõlke kasutamist alustama (2019 Language Industry Survey 2019: 10). Ka 2020. aastat käsitlevas aruandes Language Industry Survey 2020 on esile toodud, et masintõlke toimetamine (ning tehisintellekt) oli vastanud ettevõtete ja tõlkijate seas üks kõige olulisemaid tõlketeenuseid ja -turgu mõjutavaid tegureid.
Rahvusvahelise võrgustiku European Master’s in Translation (EMT) 2017. aasta pädevusraamistikus on tõlketehnoloogia ja masintõlkega seotud oskustele pühendatud oluline osa. Raamistiku nõuete kohaselt peavad võrgustiku liikmeteks olevates ülikoolides tõlkimist õppivad üliõpilased pärast õppekava läbimist teadma masintõlke toimimise põhimõtteid ja mõistma masintõlke mõju tõlkeprotsessile, oskama hinnata masintõlkesüsteemide asjakohasust tõlkimise töövoos ning rakendada vajaduse korral sobivaid masintõlkesüsteeme (European Master’s in Translation 2017: 9).
Masintõlke järeltoimetamise kohta on koostatud ka eraldi rahvusvaheline standard ISO 18587:2017.
Eespool kirjeldatu illustreerib hästi seda, kui oluliseks on tõlkevaldkonnas masintõlge muutunud. Kui võtta lisaks üldistele kasutustrendidele arvesse seda, et NMT tulemus on tihti grammatiliselt veatu, kuid võib samas olla sisuliselt täiesti vale, lisandub masintõlke olulisusele ka masintõlke järeltoimetamise tähtis roll. Masintõlke järeltoimetamise (ingl. machine translation post-editing, MTPE) definitsioone on mitmesuguseid. Esmalt tuleks tähele panna, et eestikeelne termin „järeltoimetamine“ on otsetõlge ingliskeelsest terminist post-editing ning võib valdkonnakauge inimese jaoks jääda üsna arusaamatuks. Kuna termin „toimetamine“ juba kannab endas tähendust „teksti avaldamiseks viimistlema“ (Eesti keele seletav sõnaraamat 2009 sub toimetama), siis tundub liide „järel-“ esmapilgul üleliigne olevat. Kuna aga sobiva kvaliteediga masintõlke saavutamiseks võidakse rakendada ka masintõlkesüsteemi sisendina kasutatava teksti eeltoimetamist ehk süsteemile hõlpsamini töödeldavaks muutmist, saame rääkida masintõlke toimetamisest, mis omakorda jaguneb masintõlke eel- ja järeltoimetamiseks.
Masintõlke järeltoimetamist on defineeritud näiteks järgmiselt:
- automaatse või poolautomaatse süsteemi (masintõlkesüsteemi, tõlkemälu) loodud teksti analüüsimine ja korrigeerimine, et tagada selle grammatiline, kirjavahemärgistuslik, ortograafiline ning tähenduslik õigsus (Euroopa Standardikomitee 2004: 5);
- mis tahes automaatse tõlkimissüsteemi loodud tõlgete kontrollimine, toimetamine ja korrektuur (Gouadec 2007: 25);
- masina loodud tõlke parendamine minimaalse käsitsitehtava töö abil (TAUS 2010, viidatud Screen 2017 kaudu).
Oluliseks on muutunud just sobiva kvaliteediga tõlketeksti saavutamine minimaalse hulga käsitsi tehtavate parandustega, ilma üleliigse tööta. Seda, mil määral on masintõlkesüsteemid tegelikult tõlkijatele kasulikud, ei ole väga palju uuritud ning vähe on seda loomulikult tehtud praegu kõige uuema NMT tehnoloogia puhul, aga näiteks masintõlke järeltoimetamist käsitlevast Katre Sepa magistritööst selgus, et SMT aitas tarkvaratekstide inglise keelest eesti keelde tõlkimise puhul tõlkijate kiirust suurendada keskmiselt 25% (Sepp 2017: 45). Erinevates uurimustes on tõlkimise kiiruse kasvuks saadud näitajaid vahemikus 30–300% (AMTA 2016), mis muudab järeltoimetamise atraktiivseks neile, kelle jaoks on tõlkeprotsessi efektiivsus väga oluline. Ühest küljest tundub ahvatlev saada tõlkimise kiirendamise abil näiteks rohkem tulu, kuid keeletehnoloogia professor Mark Fišel (2016) on öelnud, et kindlasti ei tohiks „tõlkimise puhul arvestada ainult ajakuluga ega inimesi tuimalt vaid järeltoimetama panna, kuna see võib kasvatada stressi ja tuua kaasa väärtuslike spetsialistide läbipõlemise“. Masintõlke järeltoimetamist võiks eelkõige näha kui võimalust lasta masinal automaatselt ära teha tõlketöö rutiinne ja igavam osa ning jätta selle loomingulisem pool inimesele (ibid.).
USA tööjõustatistika ameti Bureau of Labor Statistics (2019) andmetel võib eeldada, et tõlkide ja tõlkijate osakaal tööhõives suureneb ajavahemikus 2018-2028 tervelt 19%, mis on märksa rohkem kui kõikide muude valdkondade keskmine. Ka Eestis on SA Kutsekoda poolt tööjõuvajaduse seire- ja prognoosisüsteemi OSKA raames koostatud uuringu andmetel kirjalikus ja suulises tõlkimistegevuses majandusnäitajad olnud kindla tõusutrendiga (SA Kutsekoda 2019: 88).
Kuna tõlkemahud näitavad pigem tõusvat kui langevat trendi, võib eeldada ka jätkuvalt kasvavat huvi masintõlke arendamise ja kasutuselevõtu vastu. Mida paremini on tõlkijad kursis masintõlke arenguga ja kasutusviisidega, seda suuremat rolli saavad nad ka ise kanda oma erialase tuleviku kujundamises.
Masintõlke järeltoimetamine erineb aga oluliselt tavapärasest inimese loodud tõlke toimetamisest, mistõttu ei pruugi sugugi parim lahendus olla see, kui pikka aega tõlkimisele või inimeste loodud tõlgete toimetamisele spetsialiseerunud tõlkijad või toimetajad hakkavad ilma ettevalmistuseta masintõlget toimetama. Teatav ühisosa on nii tõlkimisel, inimtõlke toimetamisel kui ka masintõlke järeltoimetamisel küll olemas (näiteks peab kõigi puhul silmas pidama teksti sihtrühma), kuid järeltoimetamise puhul võib soovitav lõplik kvaliteeditase olla erinev ning masintõlke puhul on tõenäolised teatavad tüüpvead, mille esinemist asjakohast masintõlkesüsteemi tundes võib eeldada. Kui masintõlkesüsteem õpib kasutaja tehtud parandustest ja muutub seeläbi aja jooksul paremaks või muudab oma väljundit interaktiivselt olenevalt kasutaja sisestatust, võib öelda, et järeltoimetamise asemel on tegemist juba pigem arvuti ja inimese pidevas koostöös valmiva tõlkega (loe interaktiivse kohanduva masintõlketoega tõlkimisplatvormi Lilt kohta allpool jaotisest „Tulevikustsenaariumid“).
Kui räägime sellest, et masintõlke järeltoimetamise puhul võib soovitav lõplik kvaliteedi tase olla erinev, tähendab see seda, et tõlke soovija võib üldistatult soovida kas
- tõlget, mis on arusaadav ja annab lähteteksti sisu üldjoontes edasi (üldiselt olukordades, kus tõlget hiljem kusagil ei avaldata ja/või tõlketeksti kvaliteediga ei ole seotud olulisi riske) või
- tõlget, mis oleks samaväärne veatu ja sobiva stiiliga inimtõlkega.
Sellest lähtudes liigitatakse masintõlke järeltoimetamine tavaliselt ühte kahest kategooriast: osaline järeltoimetamine (ingl. light post-editing, LPE) või täielik järeltoimetamine (ingl. full post-editing, FPE).
Osaline järeltoimetamine
Masintõlke osalise järeltoimetamise eesmärk on eelkõige saavutada arusaadav tekst, millel on lähtetekstiga sama sisu, kuid seejuures lähtutakse põhimõttest, et kui midagi selle eesmärgi saavutamiseks tingimata muuta pole vaja, siis seda ei muudeta. Järeltoimetaja jätab masintõlgitud tekstist alles nii suure osa kui võimalik ja parandab mõnd tekstiosa üksnes siis, kui parandamata jätmine takistaks tekstist aru saamist või lähteteksti mõtte edastamist. Osalise järeltoimetamise puhul toimetaja
- kontrollib, et midagi ei ole tõlkest välja jäänud ja midagi üleliigset pole sellesse lisandunud;
- parandab ilmsed ebaõiged sõnad või laused;
- parandab teksti struktuurilisi probleeme, kui need tekitavad teksti ebaõigelt või ebaselgelt mõistmise ohu.
Osalise järeltoimetamise puhul ei pöörata eriti tähelepanu teksti stiilile ja ladususele ning oluline on mitte jääda teksti liiga kauaks viimistlema, st mitte kulutada ebavajalikult palju aega ebavajalike muudatuste tegemisele.
Täielik järeltoimetamine
Masintõlke täieliku järeltoimetamise eesmärk on teha masintõlkest inimese loodud tõlgetega võrdväärne tekst, mis oleks lisaks sisulisele õigsusele kooskõlas ka stiililiste ootustega ning tõlke soovija või valdkonna terminoloogiaga ja suunistega. Täieliku järeltoimetamise puhul toimetaja (lisaks osalise järeltoimetamise puhul kontrollitavale)
- tagab, et tekst oleks nii grammatiliselt, süntaktiliselt kui ka semantiliselt õige;
- parandab kõik õigekirjavead;
- kontrollib, et tõlkes oleks ühtselt kasutatud nõutud terminoloogiat;
- tagab, et teksti stiil oleks asjakohane ja kliendi ootustele vastav ning et tekst oleks ladus;
- tagab teksti nõuetekohase vormistuse.
Kirjeldatud järeltoimetamise tasemed ja nende puhul järeltoimetaja tähelepanu all olevad teksti aspektid on visuaalselt kokku võetud järgmisel joonisel (turu-uuringute ja konsultatsioonifirma Common Sense Advisory ja ettevõtte KantanMT materjali alusel):
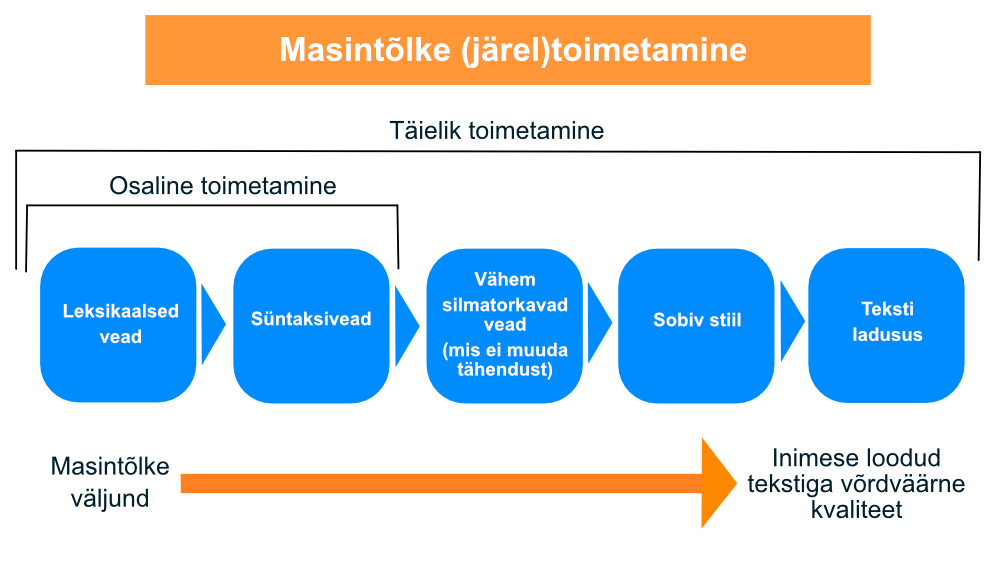
Osalist ja täielikku järeltoimetamist käsitlevad täpsed suunised koostab toimetajate jaoks tihtipeale iga ettevõte (tõlkebüroo) eraldi ning kuna need ei ole üldjuhul avalikult kättesaadavad, on nende sarnasust/erinevust ka keeruline hinnata, kuid avalikult kättesaadavate suuniste puhul on leitud, et osalise ja täieliku järeltoimetamise kriteeriumid on suures osas kattuvad (Hu, Cadwell 2016).
Masintõlke toimetamise etapid
Selleks, et (võimalike vigadega) masintõlge selle toimetajat ja toimetatavast tekstist aru saamist liigselt ei mõjutaks (nii, et ka toimetaja võib teksti selle tagajärjel hakata valesti mõistma), on oluline, et masintõlke toimetamisel läbitaks vajalikud tegevused järgmises järjekorras:
1. loe läbi lähtetekst;
2. saa lähtetekstist aru.
Alles seejärel tuleks edasi liikuda ja teha järgmist:
3. loe masintõlget;
4. tuvasta vead masintõlkes;
5. paranda vead masintõlkes.
Masintõlke järeltoimetajal peaksid olema samad teadmised ja oskused mis tõlkijal, kuid lisaks sellele on järeltoimetamise puhul vajalikud ja/või kasulikud järgmised teadmised ja oskused (O’Brien 2002: 102-103):
- tekstitöötlustarkvaraga töötamise hea oskus üldiselt;
- masintõlketehnoloogia aluste ja toimimise mõistmine;
- positiivne suhtumine masintõlketehnoloogiasse;
- kannatlikkus;
- teadmised eeltoimetamisest ja piiratud loomulikest keeltest;
- teatavad programmeerimisoskused.
Eelkõige tuleb kasuks masintõlkesüsteemide tundmine, sest see aitab järeltoimetajal otsida ja ära tunda tüüpilisi vigu. Oluline on ka oskus teha üksnes vajalikul määral parandusi ja muudatusi (mõistmine, et üks raske viga ei muuda kogu masintõlgitud lauset või teksti kasutuskõlbmatuks, sest see võib olla väga lihtsasti parandatav) ning pidada alati silmas ajakulu ja püstitatud kvaliteedieesmärki. Kui võtame arvesse seda, et NMT väljund võib olla pealtnäha täiesti veatu tõlge, kuid siiski peita endas sisulisi vigu, võib järeltoimetaja ühe olulise oskusena nimetada ka teksti kriitiliselt analüüsimise oskust. Oluline on seega tähelepanelikkus, võime kiirelt otsuseid langetada ning etteantud reeglite ja suuniste järgimine.
Eeltoimetamine (ingl. pre-editing) tähendab teksti töötlemist enne masintõlkimise toimumist. Eeltoimetamise ajal kontrollitakse ja vajaduse korral parandatakse lähteteksti õigekirjutust, kirjavahemärgistust ja vormistust, lihtsustatakse keerukamate lausete ülesehitust ja muudetakse lauseid nii, et tekst ei oleks mitmemõtteline. Selle eesmärk on muuta tekst masintõlkesüsteemi jaoks hõlpsamini töödeldavaks, et süsteemi väljund ehk tõlge oleks parema kvaliteediga. Eeltoimetamise reeglid võivad olla koostatud nii inimese- kui ka masinapoolseks järgimiseks. Kui lähteteksti eeltoimetamine muudab masintõlkesüsteemi loodava tõlke paremaks, siis lüheneb ka selle masintõlke järeltoimetamisele kuluv aeg (Gerlach, Porro Rodriguez, Bouillon, Lehmann 2013).
Mõnikord räägitakse keeletehnoloogia kontekstis ka piiratud loomulikest keeltest (ingl. controlled natural languages, CNL). Tegemist on põhimõtteliselt tehiskeeltega, mis sisaldavad ainult teatavaid osi loomulikust keelest, et olla seeläbi masinarusaadavalt töödeldavad ja hõlbustada näiteks erinevatel eesmärkidel toimuvat inimese ja masina vahelist suhtlust.
Näiteks võib teksti masintõlke jaoks eeltoimetades piirata lausete pikkust 20–25 sõnaga, sest väga pikad laused võivad NMT puhul probleeme tekitada, nagu need võivad muidugi tõlke kvaliteeti mõjutada ka inimese tehtava tõlke puhul (lühidalt ja lihtsalt soovitatakse tekste kirjutada ka Euroopa Komisjoni juhendis „Kirjuta selgelt“ (2017: 6) ning selge keele liikumine on viimasel aastakümnel taas tuule tiibadesse saanud). Küll aga ei tähenda pikemad laused tingimata seda, et eeldada võiks kehvemat masintõlget või tavapärasest keerulisemat toimetamistööd, sest näiteks masintõlkes esineda võivad terminoloogia- või üldised tähendusvead võivad olla seotud pigem masintõlkesüsteemi treeningandmetega, mitte sõnade arvuga ühes lauses.
Masintõlke tüüpvigade näited
(allikad: Google Translate, Tilde Translator, SDL plc, eTranslation)
NB! Kuna masintõlkesüsteeme arendatakse ja nende tulemusi parendatakse kogu aeg, siis võivad allpool esitatud näited juba olla parandatud või kättesaadavates levinud masintõlkesüsteemides enam mitte esineda.
| Viga | Näide | Kuidas parandada? |
| Vale tähendus / valed seosed | Europe’s excellent researchers publish the most scientific articles on AI globally.
→ Euroopa tippteadlased avaldavad maailma kõige teaduslikumad artiklid tehisintellekti kohta. Farmers could earn €90 more per acre. → Põllumajandustootjad võivad teenida rohkem kui 90 eurot aakri kohta. |
Järeltoimetamise käigus (tuvastada aitab üksnes tähelepanelik lugemine) |
| Tähenduse muutumine vastupidiseks | Whereas the shipping industry to some extent can mitigate costs by idling vessels thus avoiding fuel and terminal handling costs, the cost base of port terminals is far more inelastic in the short term.
→ Kuigi laevandussektor saab teataval määral kulusid leevendada laevade tühikäigul töötamisega, vältides seega kütuse ja terminali käitlemiskulusid, on sadamaterminalide kulubaas lühikeses perspektiivis palju elastsem. |
Järeltoimetamise käigus (tuvastada aitab üksnes tähelepanelik lugemine) |
| Terminoloogiline ebaühtlus | Tighten the lock nut. The counter nuts are not provided with the product. | Järeltoimetamise käigus, mõningatel juhtudel ka tõlkeabiprogrammi kvaliteedikontrollimoodulis koos terminibaasiga kasutatuna |
| Isikute/asutuste nimed on tõlgitud | Aruandest nähtub, et OÜ Minu Õun töötajate arv on aastaga langenud.
→ The report shows that the number of OÜ My Õun employees has decreased over the year. |
Järeltoimetamise käigus, kui ei ole näiteks tõlkeabiprogrammis ennetavalt määratud konkreetsed nimed mittetõlgitavateks elementideks (non-translatables) |
| Tõlkimata jäänud sõnad | Kolmapäeval ja neljapäeval oleme Barentsi merelt ulatuva madalrõhuala võrdlemisi tuulises lõunaservas: sageli sajab nii vihma kui lörtsi, idas ka lund.
→ On Wednesday and Thursday, the low-pressure area from the Barents Sea is comparatively windy on the southern edge: it often rains as rain and lörts, and snow in the east. |
Järeltoimetamise käigus |
| Ebaühtlane kirjaviis, lühendid valed | BDÜ asemel Bdü/BDU | Järeltoimetamise käigus |
| Väljajätud | Töös oluliste varuosade dokumentatsiooni esmane esitamine.
→ Initial submission of documentation for work-essential parts. |
Järeltoimetamise käigus |
| Kordused (neural babble) | Nutritional yeast is not the same as baking yeast or brewer’s yeast.
→ Hefehefe ist nicht dasselbe wie die Hefehefe oder die Hefehefe. |
Järeltoimetamise käigus (kuigi vähemalt üksteise kõrval olevaid korduseid aitab tuvastada ka tõlkeabiprogrammi kvaliteedikontrollimoodul) |
| Sõnaloome |
In summer one should walk along unploughed land strips between or at the edge of fields or along the bank of drainage ditches. → Suvel tuleks kõndida mööda lagedaid maariibu põldude vahel või servades või mööda kuivenduskraavide kallast. Dry, semi-dry, semi-sweet or sweet white wine with the aromas and flavours of fresh fruit, apricot and lime tree blossom, and with rich honey flavours. → Kuiv, poolkuiv, poolmagus või magus valge vein, millel on värskete puuviljade, aprikoosi ja lubjapuuõite lõhn ja maitse ning rikkalik meemaitse. |
Järeltoimetamise käigus |
| Konteksti sobimatud sõnad |
However, access is not permitted to sown crops, young crops, grain fields, plantations and apiaries, and also places where damage can be caused to the owner, even if there is no fence or no-trespassing sign. → Kuid külvatud põllukultuuride, noorte põllukultuuride, teraviljapõldude, istandike ja mesilate sissepääs pole lubatud ega ka kohtadele, kus omanikule võib kahju tekkida, isegi kui aida või ülekäigurada pole. |
Järeltoimetamise käigus |
| Vale kuupäevavorming | 04/22/2020 eestikeelses tõlkes | Tõlkeabiprogrammis kvaliteedikontrolli käigus |
| Õigekirjavead | Tõlkeabiprogrammis/tekstitöötlusprogrammis kvaliteedikontrolli käigus |
Nagu eespool esitatud näidetest võib näha, on paljud masintõlkevead (eriti sellised rasked vead nagu tähenduse muutumine) tuvastatavad üksnes teksti tähelepanelikul lugemisel ja analüüsimisel, samas kui mõned vead on automaatselt tuvastatavad ka tõlkeabi- või tekstitöötlusprogrammides.
Masintõlke järeltoimetamise näited
(Google Translate)
| Muudatused | Muudatuste määr | ||
| Lähtetekst | Every two weeks for the past 10 years, a team of scientists led by Professor Luciana Gatti, a researcher at Brazil’s National Institute for Space Research (INPE) has been measuring greenhouse gasses by flying aircraft fitted with sensors over different parts of the Amazon basin. | ||
| Masintõlge | Viimase kahe aasta jooksul iga kahe nädala tagant on Brasiilia riikliku kosmoseuuringute instituudi (INPE) teadlase professor Luciana Gatti juhitud teadlaste meeskond mõõtnud kasvuhoonegaase gaasi lennukitega, mis on varustatud anduritega Amazonase basseini eri osade kohal. | ||
| Osaline järeltoimetamine | Viimase kümne aasta jooksul iga kahe nädala tagant on Brasiilia riikliku kosmoseuuringute instituudi (INPE) teadlase professor Luciana Gatti juhitud teadlaste meeskond mõõtnud kasvuhoonegaase lennukitega, mis on varustatud anduritega, Amazonase jõgikonna eri osade kohal. | Parandatud on ilmne valetõlge aastate kohta ning termin, mis on mitmetähenduslik. Kui masintõlkes oleks olnud näiteks termin „valgala“ (terminibaasis ESTERM termini „jõgikond“ sünonüüm), siis seda poleks osalise järeltoimetamise puhul vaja muuta, aga kuna termin „bassein“ võib lugeja segadusse ajada ja takistada lähteteksti tähenduse edasiandmist, on parem see asendada. Lisatud on ka üks koma, et lauset ei oleks võimalik valesti lugeda (kuigi osalise järeltoimetamise puhul soovitatakse tavaliselt kirjavahemärgistusele mitte tähelepanu pöörata, on valetõlgenduste vältimine siiski kõige olulisem). | 6%* |
| Täielik järeltoimetamine | Viimase kümne aasta jooksul on Brasiilia riikliku kosmoseuuringute instituudi (INPE) teadlase professor Luciana Gatti juhitud teadlaste meeskond iga kahe nädala tagant mõõtnud Amazonase jõgikonna eri osade kohal kasvuhoonegaase lennukitega, mis on varustatud anduritega. | Lisaks eespool nimetatule on lause osi parema loetavuse ja täpsuse tagamiseks lihtsalt ümber tõstetud (uusi sõnu lisatud pole). |
45%* (samas on suurem osa sellest teksti tõstmine lauses ühest kohast teise) |
* Mõõtmiseks kasutati Levenshteini kauguse algoritmi, mille abil on võimalik mõõta, mitu muudatust on ühes tekstis vaja teha, et sellest saada teine tekst (näiteks siis masintõlke väljundist mingiks eesmärgiks kasutatav järeltoimetatud tekst): https://awsm-tools.com/text/levenshtein-distance
NB! Nagu ka eespool öeldud, on taolisi toimetamiskaugusel põhinevaid mõõdikuid kritiseeritud kahel põhjusel: 1) suurem masintõlkes tehtavate muudatuste arv ei tähenda alati, et masintõlge on halvem; 2) toimetamist (nagu ka tõlkimist) ja selle tasustamist ei saa taandada üksnes klahvivajutuste arvule, sest toimetaja töö hõlmab teksti sisulise õigsuse kontrollimist (mida on tegevusena märksa keerulisem mõõta), mitte üksnes tähemärkide sisestamist või kustutamist (vt näiteks Iizuka 2019).
Kuna keeletehnoloogia ja masintõlke areng on niivõrd suure mõjuga, räägitakse aina rohkem ka tõlkija elukutse kaugemast tulevikust. Euroopa Komisjoni kirjaliku tõlke peadirektoraadi eesti keele osakonna juhataja Heiki Pisuke on seisukohal, et tulevikus on tõlkija roll tõenäoliselt olla pigem „toimetaja, laiemas plaanis aga kultuuri- ja informatsiooni vahendaja, kelle töö põhifunktsioon on kommunikatsioon“ (Pisuke 2019).
Professor Sharon O’Brien (2020) on esile tõstnud neli võimalikku tulevikuversiooni, mille masintõlketehnoloogia areng võib endaga kaasa tuua:
- inimeste loodud tõlgetest saab üksnes ajalugu;
- tehisintellekti areng on lihtsalt ülespuhutud ja liigne reklaam ning tegelikult midagi väga suurel määra ei muutu;
- tehisintellektil põhinev masintõlge hakkab tõlkima madala prestiižiga tekste/sisu, inimesed aga tõlgivad kõrgema prestiižiga tekste/sisu;
- tekib teatav inimese ja tehisintellekti sümbioos.
Uuemad nähtused
- Masintõlge ja tõlkemälu ei ole enam kaks eraldiseisvat tõlkeabitarkvara moodulit, vaid sulanduvad üheks. Masintõlge asendab tõlkemälu funktsiooni seal, kus tõlkemälu ei ole piisavalt hea sisuga ning leidub ka arvamusi, et eraldi tõlkemälu pole masintõlketehnoloogia arenedes enam varsti asjakohane, sest ei saa näiteks kindlalt väita, et osaline tõlkemäluvaste on alati parem kui masintõlkesüsteemi soovitus (vt näiteks Fairman 2019).
- Masintõlke järeltoimetamine ei toimu enam tingimata eraldiseisva etapina, vaid on muudetud tõlkimise üheks lahutamatuks osaks. Interaktiivsel ja kohanduval tõlkeplatvormil Lilt (https://lilt.com/solutions) pakub masintõlkesüsteem tõlkijale juba tõlke trükkimise ajal jooksvalt võimalikke sobivaid tõlkelahendusi ning muudab pakutavat kohe selle järgi, mida tõlkija süsteemi trükib.
Mõned aktuaalsed masintõlke arengu ja toimetamisega seotud probleemid on järgmised:
- masintõlke võimalik kallutatus (eelkõige seetõttu, et juba sisendtekst on mingil viisil kallutatud);
- teatav mure selle üle, kuidas mõjub masintõlketehnoloogia keele leksikaalsele mitmekesisusele;
- eetikaga, autoriõigustega ja vastutusega seotud eri probleemid (sarnaselt kogu tehisintellekti valdkonnas esile kerkivatele küsimustele).
– 2019 Language Industry Survey – Expectations and Concerns of the European Language Industry 2019. Kättesaadav aadressil https://euatc.org/wp-content/uploads/2019/11/2019-Language-Industry-Survey-Report.pdf (08.02.2020)
– Callison-Burch, C; Osborne, M; Koehn, P. 2006. Re-evaluating the Role of Bleu in Machine Translation Research. 11th Conference of the European Chapter of the Association for Computational Linguistics, Trento, Itaalia, aprill 2006. Kättesaadav aadressil https://www.aclweb.org/anthology/E06-1032/ (08.02.2020)
– Eesti keele seletav sõnaraamat 2009. Tallinn: Eesti Keele Sihtasutus. Kättesaadav aadressil http://www.eki.ee/dict/ekss/index.cgi (10.02.2020)
– Euroopa Komisjoni kirjaliku tõlke peadirektoraat. 2017. Kirjuta selgelt. Kättesaadav aadressil https://op.europa.eu/et/publication-detail/-/publication/bb87884e-4cb6-4985-b796-70784ee181ce (27.10.2020)
– Euroopa Standardikomitee 2004. Kättesaadav aadressil http://web.letras.up.pt/egalvao/prEN-15038.pdf (10.02.2020)
– European Master’s in Translation 2017. Competence Framework 2017. Kättesaadav aadressil https://ec.europa.eu/info/sites/info/files/emt_competence_fwk_2017_en_web.pdf (09.02.2020)
– Fairman, Gabriel 2019. The Death Of Translation Memory In Localization: Three Key Takeaways And Key Advice. Forbes. Kättesaadav aadressil https://www.forbes.com/sites/forbestechcouncil/2019/11/08/the-death-of-translation-memory-in-localization-three-key-takeaways-and-key-advice/#5092a5fe5792 (12.02.2020)
– Fišel, Mark 2016. Milline on hea masintõlge? Sirp. Kättesaadav aadressil https://www.sirp.ee/s1-artiklid/varia/milline-on-hea-masintolge/ (10.02.2020)
– 2020. Prof Mark Fišeli inauguratsiooniloeng „Tasuta lõuna“. Kättesaadav aadressil https://www.uttv.ee/naita?id=29281&keel=eng (12.02.2020)
– 2020. Tehisintellekti Algkursus, 5. OSA. Keeletehnoloogia. Kättesaadav aadressil https://courses.cs.ut.ee/2020/Tehisintellekti_algkursus/Main/PARTVnlp (27.10.2020)
– Forcada, Mikel L. 2017. Making sense of neural machine translation. Translation Spaces 6:2 (2017) 291–309. Kättesaadav aadressil https://www.dlsi.ua.es//~mlf/docum/forcada17j2.pdf (08.02.2020)
– Gerlach, Johanna et al. 2013. Combining pre-editing and post-editing to improve SMT of user-generated content. Proceedings of MT Summit XIV Workshop on Post-editing Technology and Practice. Nice, Prantsusmaa, 2.09.2013. Kättesaadav aadressil https://archive-ouverte.unige.ch/unige:30952 (10.02.2020)
– Gouadec, Daniel 2007. Translation as a Profession. Amsterdam, Philadelphia: John Benjamins Publishing Company
– Hu, Ke; Cadwell, Patrick. 2016. A Comparative Study of Post-editing Guidelines. Baltic Journal of Modern Computing, Vol. 4 (2016), No. 2, 346-353. Kättesaadav aadressil https://www.bjmc.lu.lv/fileadmin/user_upload/lu_portal/projekti/bjmc/Contents/4_2_23_Hu.pdf (27.10.2020)
– Iizuka, Izabella. 2019. Edit Distance: Not a Miracle Cure. Kättesaadav aadressil https://blog.sdl.com/blog/edit-distance-not-a-miracle-cure.html (27.10.2020)
– Koponen, Maarit 2016. Is machine translation post-editing worth the effort? A survey of research into post-editing and effort. The Journal of Specialised Translation 25 (2016): 131–148. Kättesaadav aadressil https://www.jostrans.org/issue25/art_koponen.pdf (08.02.2020)
– European Language Industry Survey 2020, Before & After COVID-19. Kättesaadav aadressil https://ec.europa.eu/info/sites/info/files/2020_language_industry_survey_report.pdf (27.10.2020)
– Liin, Krista jt. 2012. Eesti keel digiajastul = The Estonian language in the digital age. Springer. Kättesaadav aadressil https://www.digar.ee/arhiiv/nlib-digar:121285 (30.01.2020)
– Nieminen, Tommi 2020. Konekäännös suomalaisen kääntäjän näkökulmasta (MT from the point of view of a Finnish translator). Translating Europe Workshop “Machine translation and the human translator”, Tampere, Soome, 31.01.2020. Kättesaadav aadressil https://moniviestin.uta.fi/videot/tuni-2019-2020/tapahtumat/translating-europe-workshop/recording-03-02-2020-14.18 (08.02.2020)
– O’Brien, Sharon 2002. Teaching Post-editing: A Proposal for Course Content. 6th EAMT Workshop “Teaching machine translation”,14.-15. november 2002, 99–106. Kättesaadav aadressil http://www.mt-archive.info/00/EAMT-2002-OBrien.pdf (05.12.2018).
– O’Brien, Sharon 2020. The Future of Translator Training in the MT Era. Translating Europe Workshop “Machine translation and the human translator”, Tampere, Soome, 31.01.2020. Kättesaadav aadressil https://puolukka.uta.fi/~textmine/events/tew-tampere/OBrien_Tampere_Jan2020.pdf (12.02.2020)
– Pisuke, Heiki 2019. Tõlkimisest Euroopa Liidu institutsioonides. Keel ja Kirjandus 1-2/2019: 69–84. Kättesaadav aadressil http://kjk.eki.ee/ee/issues/2019/1-2/1132 (10.02.2020)
– Poibeau, Thierry 2017. Machine Translation. Cambridge, London: The MIT Press
– SA Kutsekoda 2019. Tulevikuvaade tööjõu- ja oskuste vajadusele: kultuur ja loometegevus: audiovisuaalvaldkond, sõna ja keel, turundus ja kommunikatsioon, disain ja kunst, trükitööstus. Tallinn: SA Kutsekoda. Kättesaadav aadressil: https://oska.kutsekoda.ee/wp-content/uploads/2017/10/Uuringuaruanne_-kultuur-ja-loometegevus_-2.pdf (10.02.2020)
– Screen, Ben 2017. Machine Translation and Welsh: Analysing free Statistical Machine Translation for the professional translation of an under-researched language pair. The Journal of Specialised Translation 28 (2017): 317–344. Kättesaadav aadressil https://www.jostrans.org/issue28/art_screen.pdf (10.02.2020)
– SDL plc. 2018. SDL Post-Editing Certification, Machine Translation Post-Editing
– Sibul, Ingrid 2018. Masintõlge ja eestikeelsed õigustekstid –ühe tõlkija senised kogemused Euroopa Komisjonis. Õiguskeel 2018/2. Kättesaadav aadressil https://www.just.ee/sites/www.just.ee/files/ingrid_sibul._masintolge_ja_eestikeelsed_oigustekstid_-_uhe_tolkija_senised_kogemused_euroopa_komisjonis.pdf (09.02.2020)
Kasulikku:
– Tehisintellekti käsitlev tasuta veebikursus „Elements of AI“: https://www.elementsofai.ee/
– Tartu Ülikooli arvutiteaduse instituudi tehisintellekti algkursus: https://courses.cs.ut.ee/2020/Tehisintellekti_algkursus/Main/HomePage
Masintõlke toimetamise õppevahendi on koostanud Reelika Saar (reelika.saar@ut.ee). Õppevahend on loodud HITSA projektis „IKT-alase võimekuse suurendamine ning digihumanitaaria arendamine Tartu Ülikooli humanitaarteaduste ja kunstide valdkonnas“.