MRI bioinformaatika töögrupp
Uurimisteemad
LÕPUTÖÖDE TEEMAD ÜLIÕPILATELE
Bioinformaatika uurimisgrupis on üliõpilastel võimalik teadustöös osaleda mitmesugustes erinevates projektides erinevatel tasemetel (3+2 lõputööd, magistriõpe, doktoriõpe).
Meie üldine eesmärk on arendada arvutusalgoritme genoomijärjestuste usaldusväärseks ja kiireks analüüsiks. Mõned näited:
* antimikroobse resistentsuse ennustamine ja plasmiidide tuvastamine bakteri genoomse DNA järjestusest;
* mikroobsete patogeenide DNA tuvastamine inimese verest (rakuvaba DNA fraktsioonist) või muudest allikatest;
* toidu koostise, päritolu ja puhtuse määramine toidus leiduva DNA abil.
Huvi korral pöörduge vastava projekti läbiviija või uurimisgrupi juhi (prof. Maido Remm) poole.
VARASEMAD ja PRAEGUSED UURIMISTEEMAD
1. Bakterigenoomide järjestuste arvutuslik analüüs, bakteritüvede virulentsuse ning antibiootikumi resistentsuse ennustamine genoomi järjestuse alusel
Viimasel ajal oleme osalenud paljudes suurtes koostööprojektides, kus sekveneeritakse sadu või tuhandeid bakteri isolaate. Oleme testinud ja arendanud arvutuslikke tööriistu, mis on vajalikud nendes projektides tekkivate genoomijärjestuste analüüsiks.
Iga uuritav genoom on vaja assambleerida, seejärel teostatakse neile liigi kontroll (kas sekveneerimiseks korjati õige bakteriliik), saastuse kontroll (ega teisi liike andmetes sees ei ole), MLST tüübi määramine, tuumikgenoomi puu ehitamine, resistentsusgeenide otsimine,
resistentsusgeenide konteksti (ümbritsevate geenide) analüüs, plasmiidide olemasolu ennustamine ja plasmiidide kirjeldamine.
Üks tähtsamaid eesmärke bakterigenoomide uurimisel on nende bakterite omaduste ennustamine järjestuse alusel. Enamasti on ennustatavateks omaduseks virulentsus või resistentsus erinevatele antimikroobsetele ainetele. Selles valdkonnas oleme oma töögrupiga asunud aktiivselt arendama vastavaid ennustusmudeleid. Meie ennustusmudelite sisendiks on uuritava bakteritüve DNA järjestus, selle alusel peaks mudel suutma ennustada millistele antibiootikumidele antud bakteritüvi on resistentne. Lisaks võimalusele kasutada resistentsuse ennustusmudeleid meditsiinilises diagnostikas, võimaldavad sellised mudelid ka teada saada millised geenid osalevad resistentsuse tekkes.
2. DNA järjestusel põhinevate diagnostiliste testide arendamine
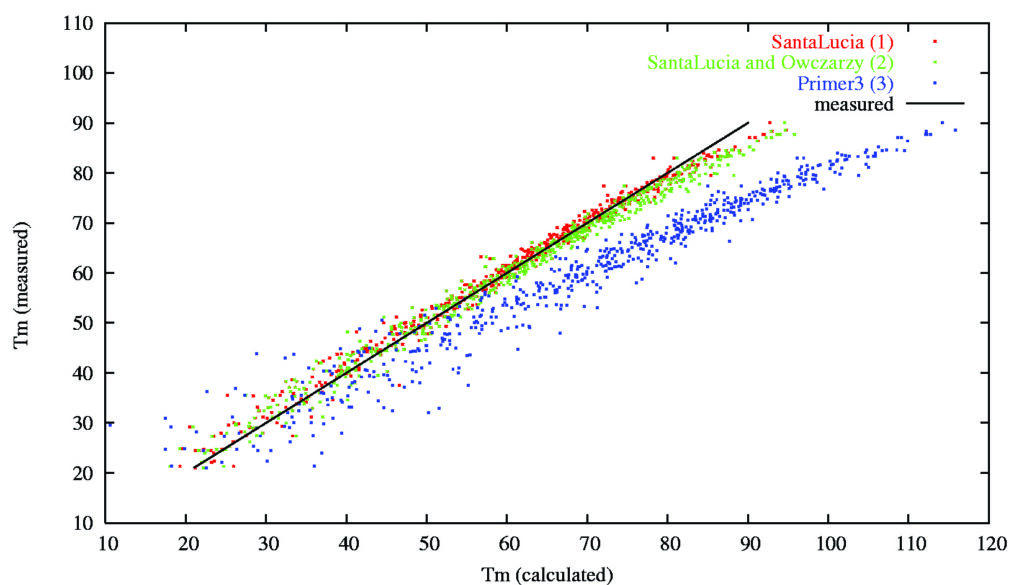
Oleme oma uurimisgrupis juba rohkem kui 10 aastat uurinud DNA ahelate omavahelist paardumist ja DNA ahela pikenemist polümeraasi ahelreaktsiooniga (PCRiga). DNA ahelate paardumine on aluseks paljudele molekulaarbioloogilistele meetoditele, seetõttu on oluline mõista ja ennustada milline DNA järjestus võib teistega paarduda ja kuidas see protsess täpselt realiseerub. Meie tegevus hõlmab DNA paardumise biokeemilist modelleerimist ja vastava tarkvara kirjutamist. Meie töörühm on laialt levinud praimerite disaini programmi Primer3 (Untergrasser jt. 2013, Kõressaar jt., 2018) üks peamistest arendajatest. Oleme aidanud luua diagnostilisi teste haigustekitajate avastamiseks patsientide proovidest AS-le Quattromed HTI (praeguse nimega SynLab Eesti OÜ) ja toiduallergeenide DNA avastamise teste koostöös AS-ga Icosagen. Oleme arendanud välja diagnostilise testi vastsündinute sepsise põhjustajate leidmiseks koostöös Hollandi ettevõttega Microbiome (van den Brand et al., 2014). Publitseerimisel on meie poolt arendatud multipleks-PCR testid, mis võimaldavad Listeria monocytogenes ohtlikke tüüpe senisest kiiremini määrata.
Praegu on DNA sekveneerimise hind niivõrd madal, et arendustöö rõhk on liikunud DNA sekveneerimisel põhinevaid diagnostiliste testide arenduseks. DNA sekveneerimise suur eelis PCRi ees on selles, et kui PCR test võimaldab tuvastada vaid ühte patogeeni ühe testiga, siis sekveneerimine võimaldab analüüsida kõiki uuritavas proovis olevaid liike korraga.
Hetkel arendame:
a) inimese vereproovist sepsise patogeenide tuvastamise testi;
b) toidupatogeenide tuvastamise teste;
c) toiduainete koostise ja päritolu määramise teste (Raime ja Remm, 2018; Raime et al., 2020).
3. Kiirete arvutusmeetodite arendamine inimese personaalsete genoomide analüüsiks
Varasematel aastatel oleme koostanud mitmeid originaalseid meetodeid inimeste personaalsetest genoomijärjestustest erinevate variantide leidmiseks.
* FastGT leiab 30 minutiga kõik varem kirjeldatud ühenukleotiidsed variandid ja indelid (Pajuste jt. 2017);
* KATK leiab kõik indiviidi erinevused referentsgenoomist ca 3 tunniga (Kaplinski et al., 2021);
* oleme loonud metoodika Alu kordusjärjestuste insertsioonide tuvastamiseks indiviidide genoomidest (Puurand jt., 2019);
* oleme arendanud meetodeid geenide (näiteks amülaasi geeniperekonna) koopia arvude leidmiseks (Pajuste jt., 2023);
* oleme arendanud meetodeid VNTR kordusjärjestuste koopia arvude leidmiseks (Örd jt.,2020);
* Y-mer määrab inimese chrY haplogruppe madala sekveneerimissügavusega andmetest (Puurand jt., 2025).
Meie meetodid kasutavad tavapärasest erinevat, signatuur-järjestustel põhinevat lähenemist ja on seetõttu ca 30 korda kiiremad traditsiooniliselt kasutatavatest meetoditest, seejuures kaotamata täpsuses.
